
Ужасы нейронных сетей. Часть 7: История нейросетевой генерация речи. Часть 1: От поющего IBM до разговорчивой Алисы
 ithitym
ithitym
С синтезом речи связано очень много преступных схем: от клонирования голоса до создания полностью фейковой личности. Но прежде чем приступить к разбору вреда, нужно понять, как этот синтез устроен. В этой части поговорим о первых разработках в области нейросетевого синтеза и о том, как эти технологии совершенствовались.
Если вы впервые видите эту серию статей и удивились цифре 7 в названии, то я вас поздравляю! У вас впереди несколько часов увлекательного чтива, затрагивающего разные аспекты нейросетей: от юридических тонкостей авторских прав и случаев ложных обвинений на основе результатов ИИ до истории работы вокалоидов и руководства предостережения о методах доксинга при помощи чат-ботов. Это и многое другое вы можете прочесть в предыдущих частях.
Все «Ужасы нейронных сетей»
- Ужасы нейронных сетей. Часть 1: Нейросети и авторское право
- Ужасы нейронных сетей. Часть 2: На каких ваших данных обучаются нейросети
- Ужасы нейронных сетей. Часть 3: Как сделать шапочку из фольги или стоит ли опасаться ИИ?
- Ужасы нейронных сетей. Часть 4: Генерация и распознавание лиц
- Ужасы нейронных сетей. Часть 4.5: Clearview AI и ложные обвинения
- Ужасы нейронных сетей. Часть 5: Распознавание речи
- Ужасы нейронных сетей. Часть 6: Типы синтеза речи. От Стивена Хокинга до Хатсуне Мику
- Ужасы нейронных сетей. Часть 7: История нейросетевой генерация речи. Часть 1: От поющего IBM до разговорчивой Алисы
Итак, как уже поняли по названию, речь пойдёт о нейросетевом синтезе речи. Его мы слышим часто: озвучка донатов у стримеров, зачитывание комментов у блогеров или пересказ фильма в Тик-Ток. Но как развивался синтез и каким образом он работает?
Чтобы одновременно напомнить, о чём мы ранее говорили, и связать эту статью с предыдущей, предлагаю посмотреть краткий ИИ-пересказ, который набросал в NotebookLM. Кстати, довольно интересная штука, рекомендую ознакомиться.

Монтаж, слайды и озвучка — всё сделано в нейросети
Весь ролик был сгенерирован всего одним коротким промтом (и ссылкой на предыдущую статью в качестве источника). Обратите внимание на качество синтезированного голоса и его широкий спектр интонаций. Слышно даже, как диктор набирает воздух перед началом предложения. Поразительное качество! Но как же его достигли? Для этого надо вспомнить, с чего всё начиналось.
60-е: Daisy, Daisy
Ещё до зарождения машинного обучения, в далёком 1961 году, в Bell Labs кипела работа. Там проводились исследования в области синтеза речи и учёные ломали голову над странной на первый взгляд задачей: как заставить громоздкий механизм под названием IBM 7094 — петь. В итоге у них получилось. Машина запела старую песню 1892 года, которую вы возможно даже недавно слышали:
Daisy, Daisy,
Give me your answer, do!
I'm half crazy,
All for the love of you!
It won't be a stylish marriage,
I can't afford a carriage,
But you'll look sweet upon the seat
Of a bicycle built for two!

Композиция «Daisy Bell (Bicycle Built for Two)» стала первой в истории песней, которую спел компьютер. Событие было столь значимым что этот факт вошёл в Книгу рекордов Гиннесса (правда на их сайте стоит дата на год раньше и устройство IBM 704), а сама композиция вошла в Национальный реестр аудиозаписей Библиотеки Конгресса (а вот тут уже значится 1961. Кому верить — непонятно).
Запись стала культовой. Её вы могли услышать в Космической Одиссее Стенли Кубрика или же в недавней серии Удивительного Цифрового Цирка. Даже голосовые помощники такие как Alexa и Cortana могли сделать на неё отсылку. Но какая прорывная технология стояла за этим рекордом? Сейчас объясню.

В то время о нейронном синтезе даже речи и не шло, так что выкручивались как могли. Для синтеза звука использовалась модель голосового тракта, получившая название Kelly-Lochbaum Vocal Tract Model в честь её изобретателей. Эта модель основывалась на соединённых трубках с цилиндрическими полостями. Звук, проходя через цилиндры, отражался и менял своё звучание. Более детально вы можете прочесть в этой статье, но если очень грубо обобщить, это как формантный синтез, но с трубками вместо формантных фильтров. На входе подаётся звук который проходя через серию трубок с разными пустотами меняет звучание. Вот как это выглядит на практике.

Только с маленьким таким различием. Трубки были цифровыми. Вся модель была программно смоделирована на основе физических принципов. Для тех кто хочет ознакомиться с моделью работы поближе, оставляю ссылку на статью Стэнфордского университета.
Но такая система синтеза не получила дальнейшего развития, уступив более практичным методам.
80-е — 90-е: зарождение нейросетей и NETtalk
Ранние попытки нейронного синтеза голоса были ещё в 90-х. Речь не шла о полном синтезе. Машинное обучение применялось в отдельных компонентах. Например, для написания фонетической транскрипции текста. Эта нейросеть называлась NETtalk. Она состояла из нескольких частей: на ввод поступал массив информации, который, проходя через скрытые слои нейронов, разбирался на понятные системе математические расчёты. И по итогу, на основе нейронов, обученных в предыдущем шаге, система генерировала выходные данные. Это очень упрощённый принцип работы нейросетей, чуть ниже его дополню, но если визуализировать, получится такая схема:
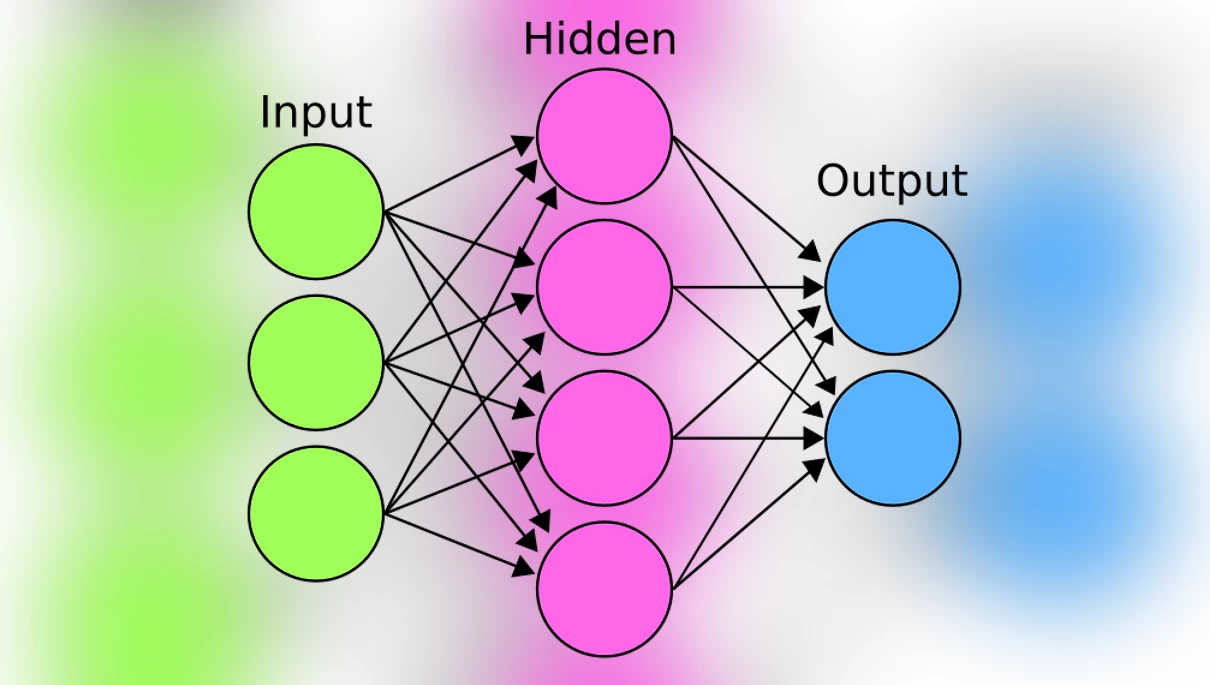
На вход NetTalk давались английские слова, которые поступали в скрытый слой из нейронов. (Стоит заметить, что это была примитивная нейронная сеть, состоящая из единственного слоя из 80 скрытых нейронов.) В этом слое происходили вычисления, благодаря которым на выходе генерировалась фонетическая транскрипция, которую синтезатор мог озвучить.
И на то время результат был вполне себе неплох.

Нечто похожее проводили исследователи из Motorola, описавшие процесс в работе Speech Synthesis with Neural Networks. Их метод синтеза основан на time-delay neural network (TDNN). Она тоже подготавливала данные для озвучивания и её структура была похожа на NetTalk но в отличие от онной учитывала контекст, т.е. предыдущий результат операции, для более лучшего качества выдачи. Система состояла из двух основных нейросетей заточенных под определённые задачи. Принцип действия был таков:На ввод подавался текст, который первая нейросеть преобразовывала в фонетическое и акустическое представление.
Далее вторая нейросеть рассчитывала длительность для каждой отдельной фонемы.
Результаты первых двух шагов складывались в окончательное акустическое описание кадра (отрывка длительностью в 10мс).
Данные передавались на вокодер, специальный компонент преобразовывающий данные в звуковой сигнал. Вокодер не был нейронным, так как иначе это бы слишком много ресурсов отнимало.
Но нейросетевое древо со скрытыми слоями не единственное, что роднит систему, сделанную 30 лет назад, с сегодняшними моделями. Ещё у них общий и принцип обучения, основанный на системе обратного распространения ошибки (backpropagation). Не пугайтесь этого термина, принцип его работы довольно интересный и занимательный.
Чтоб было понятнее, представьте себе контрольную по математике. Вы долго думаете, но не очень понимаете, как её решить. А от результатов зависит ваша итоговая оценка, поэтому что-то написать надо. Поэтому с горем пополам расписываете задачу и приходите к какому-то ответу, в котором не сильно уверены. Тут вы краем глаза, абсолютно случайно, у отличника за соседней партой замечаете открытую тетрадь. Успеваете увидеть только конечный результат вычислений, но он, заметив ваш пристальный взгляд, закрывает тетрадь. Вы записываете подсмотренный результат и начинаете думать над тем, каким образом этот скупой человек пришёл к таким выводам. Т. е. вы, зная правильный ответ, анализируете, где допустили ошибку в расчётах, дабы в дальнейшем понимать, как решать подобные задачи.

То же самое относится и к нейросетям. Сначала им скармливают массив данных, который переваривается на паттерны и преобразовывается в веса и смещения в нейронах.
Но чтоб понять, насколько верно нейросеть усвоила материал, на выход даётся образец, который машина сравнивает со своим результатом и прогоняет через веса в обратном направлении, корректируя свои шестерёнки, чтобы искажений было меньше. И таким образом нейросеть просматривает миллионы образцов, стремясь уменьшить функцию потерь (числовое обозначение серьёзности ошибки). К слову, в больших языковых моделях эту функцию практически невозможно свести к нулю, но об этом поговорим в следующий раз, когда доберусь до объяснения галлюцинаций. Возвращаемся к нашим баранам, нейронам.
Если хотите разобраться самостоятельно в принципе работе, прикрепляю хорошее объяснение от 3Blue1Brown.

На тот момент у этого метода был огромный минус, связанный с затуханием сигнала. Если у нейросети было больше определённого количества слоёв, то сигнал не доходил до начала и затухал (как энергошар из Portal). Для сохранения сигнала были разработаны несколько решений (например, ReLU или LSTM), но до их практического применения в нейронном синтезе оставалось ещё уйма времени. Поэтому пока поговорим о другом типе синтеза, который использовался до эпохи нейросетей.
2000-е: Цепи Маркова
Технологии не стояли на месте, и уже в 00-х появились сети, работающие на основе цепей Маркова, а точнее, на скрытой марковской модели (hidden Markov model, сокр. HMM). Марковские цепи легли в основу многих повседневных штук, например, благодаря им поисковик находит нужный сайт, а телефон понимает, какое слово хотите написать. Тема её реализации очень интересная, но, чтоб не углубляться во все эти мудрёные штуки, рекомендую посмотреть интересный ролик Veritasium (особенно если хотите узнать, как связаны задетое эго русского академика, «Евгений Онегин», ядерная бомба и Google).

HMM использовали значимые компании того времени, среди которых: Toshiba, Microsoft и Google. Но обратить внимание хотел на проект Festival от The Centre for Speech Technology Research (CSTR), предоставляющий свободную систему синтеза речи для Linux (Но можно и под Windows запустить). Последняя версия программы от 2017 года, включает в себя более 15 английских голосов. Сейчас к сожалению сайт выглядит заброшенным, но до сих пор доступна документация и ссылки на проект. Среди встроенных голосов есть и те, которые основаны на HTS (Hidden Markov Model-based Text-to-Speech), вот пример звучания.

К слову, можно самим создавать голос для Festival, с помощью вспомогательной программы FestVox и подробной обучающей документации к ней.
Занимательный факт: В предыдущей части я рассказывал об RHVoise, свободной TTS системе которую делает слепой программист вместе с сообществом. Так вот, в основе механизмов её работы тоже лежит HTS. Вот что об этом говорится на Хабре:
В своей работе синтезатор использует статистический параметрический синтез и был основан на наработках уже существующих проектов, таких как HTS, и опубликованных научных исследованиях. Это гибридная глубокая нейронная сеть, работающая со скрытой марковской моделью. Задача таких сетей, это разгадка неизвестных параметров на основе наблюдаемых. Можно считать, что это простейшая Байесовская сеть. Сам HTS был основан на наработках другого проекта — HTK. Но нас тут больше всего интересует, что часть наработок была опубликована для свободного использования, включая описание алгоритмов и примененных техник.
Всё таки круто что некоторые люди сознательно публикуют свои работы, дабы внести вклад в общечеловеческое благо. Но я опять отвлёкся, движемся дальше.
На скрытых марковских моделях работал и синтез речи в сервисе Yandex SpeechKit, который предоставлял услуги по распознаванию и синтезу речи как на платной, так и на бесплатной основе. Настройку можно посмотреть в этом импровизированном голосовом стендапе (который озвучен сворой других Text-to-speech голосов).

К слову, такое качество было у тогдашних TTS-систем, основанных на параметрическом и конкатенативном синтезе. Среди них вы наверняка заметили очень запоминающийся мужской голос. Это легендарный Ivona Maxim, который применялся в продуктах Amazon (например, в Amazon Kindle). В своё время он был очень популярен и использовался для озвучки донатов, зачитки текста или в телепередачах. К примеру, в выступлениях Прозрачного Гонщика, по типу этого:

Бот Максим, как его привыкли называть в простонародье, работает на основе конкатенативного синтеза, а основан на голосе Сергея Костылёва — актёре дубляжа который являлся диктором канала Discovery. Если хотите поэкспериментировать с голосами, можете озвучить ими любой текст на сайте предоставляющем TTS системы. Ну а мы движемся дальше.
2013: Глубокие исследования в области Deep Neural Network

С 2013 начались активные исследования в области нейронного синтеза речи. Они положили начало будущим открытиям и коммерческим продуктам. До этого времени для синтеза речи использовали преимущественно другие, более привычные подходы.
С 2013 по 2015 выходили разные исследования и статьи на тему нейросетей. К примеру исследователи из Google и Microsoft, пришли к выводу что нейросетевой подход превосходит HMM метод. Но следует понимать что с момента исследований, до их внедрения в коммерческие продукты, обычно необходимо продолжительное время, поэтому следующий этап развития наступил через пару лет.
2016-2017: Начало новой эры

Следующий скачок произошёл в 2016-2017 годах. Эти года были довольно значимыми для нейронных сетей и синтеза речи в частности, так что в этой статье смогу обозреть лишь часть из них.
Одними из первых хочу поговорить о голосовых ассистентах. В прошлых статьях я не раз упоминал случаи, происходившие из-за умных помощников, но ни разу не касался того, как они устроены. Тема довольно обширная, так что в этой статье разберу только устройство их голоса.
И начну пожалуй с помощника, чей голос вы наверняка уже слышали, Яндекс Алисы.
2017: Яндекс Алиса
Хочу начать с этого ассистента, так как моё знакомство с умными чат-ботами началось именно с неё. Тогда ответ ассистента казался мне чем-то очень крутым и инновационным. Подкупало ещё то, что голос не только отвечал на запросы, но и имел особое чувство юмора. Естественно, до Марвина из «Автостопом по Галактике» ещё далековато, но на тот момент это действительно было в новинку.
Алиса появилась в 2017 году, и была прорывным шагом для Яндекса в плане нейронных сетей. На тот момент у них уже был проект Yandex SpeechKit, довольно успешный сервис по распознаванию и синтезу речи работающего на скрытых марковских моделях. Но их не устраивало качество голоса, которое абсолютно не подходило для помощника, чей голос человек мог слышать десять раз на дню. Поэтому они пошли другим путём. Но это я забегаю вперёд. А пока поговорим о том, что, а вернее кто послужил основой для голосовой модели.
Как помните по прошлым частям, для модели нужны входные данные, чтоб было от чего отталкиваться. Так было и тут. Голос Алисы основан на популярной актрисе дубляжа Татьяне Шитовой, которая читателю может быть знакома по дубляжу Марго Робби (Харли Квинн), Эммы Стоун (Круэлла) и Скарлетт Йоханссон (Чёрная Вдова). Примечательно, что ранее Татьяна озвучила ОС с искусственным интеллектом Саманту в фильме «Она». Другие её роли можно услышать в этом видео.

В одном из интервью, Татьяна вспоминала первые месяцы работы над чат-ботом. Поначалу это был довольно утомительный процесс, как для самой Татьяны, так и для работников студии, так как записывали всё подряд, потому что ни кто не понимал, какой должна быть Алиса, да и к тому же из за монотонной работы был большой процент брака. Позже тексты начали вычищать и структурировать по тематике (медицинский корпус, художественная литература и т.д). или интонации (например вопросительной). Ей приходилось озвучивать очень объёмный массив текстов: от отдельных букв и слов, до предложений. Хотя почему «приходилось»? Как вы помните для лучшего качества нейросетевой выдачи нужна обучающая база размером «чем больше, тем лучше», поэтому Татьяна и сейчас озвучивает ассистента. По словам актрисы дубляжа, этот процесс бесконечный. ЕвропаПлюс приводит её слова
Я всё время, пока ещё первый выпуск «Алисы» писали, а это и так очень долго длилось, я думала, что эту «книжку» мы закрыли, и я пошла дальше. Но мне мои друзья, которые как раз и занимаются этой технологией, вот они мне сказали: «Тань, ты что, ты что! Всё только начинается!» А я говорю: «Как только начинается, всё уже закончилось, всё вышло!» — и вот нет, уже шестой год идёт, и вплоть до того, что мы её и сейчас пишем
Но это мы забегаем вперёд, давайте притормозим и вернёмся в 2007 2017 год. Хочу напомнить как Алиса звучала в то время.

Как вы можете слышать, её ответы отличались от нынешних: отвечала белиберду, не запоминала нить разговора, а её голос был ненамного лучше Glados из первого Portal, словно лоскутки фраз соединялись в одно предложение. Почему так? Ответ находится ниже.
Может возникнуть вопрос: почему бы им просто не закинуть всё в нейронку и сразу не получить нужный звук? В то время технологии на основе машинного обучения были всё ещё очень медленными и не подходили для генерации в реальном времени. Об этом компания писала в своём блоге.
Тогда как раз набирал обороты нейропараметрический подход, в котором задачу вокодера выполняла сложная нейросетевая модель. Например, появился проект WaveNet на базе свёрточной нейросети, которая могла обходиться и без отдельной акустической модели. На вход можно было загрузить простые лингвистические данные, а на выходе получить приличную речь. Первым импульсом было пойти именно таким путём, но нейросети были совсем сырые и медленные, поэтому мы не стали их рассматривать как основное решение, а исследовали эту задачу в фоновом режиме. На генерацию секунды речи уходило до пяти минут реального времени. Это очень долго: чтобы использовать синтез в реальном времени, нужно генерировать секунду звука быстрее, чем за секунду.
WaveNet о котором упоминается в цитате, это прорывная технология анонсированная компанией DeepMind (принадлежит Google) в 2016 году. Она могла выдавать очень реалистичное аудио (Причём не только голос, но и музыку) и обгоняла все существующие на тот момент аналоги. В том же году Google опубликовала статью о её работе, где можете послушать примеры и сравнение с другими типами синтеза.
О развитии WaveNet поговорим в следующей статье, но самое главное, что нужно знать: качество выхода нивелировалось скоростью работы. Поэтому для Алисы этот метод не подходил.
Но что тогда делать? Решили соединить нейропараметрический подход с другим, который позволял быстро формировать и выводить фразы. А знаете, как он называется? Я о нём, между прочим, в прошлой части говорил. Давайте напомню основные типы:
- Фонемный — когда звук, проходя через фильтры, превращается в понятные буквы. Пример: голос Стивена Хокинга, «Perfect Paul».
- Параметрический — предсказывает благозвучную последовательность звуков, опираясь на сам текст, знаки препинания и правила построения слов. Пример: TTS, в частности RHVoice.
- Компилятивный (он же конкатенантивный) — склейка из отрезков речи (слогов, слов а порой и предложений), находящихся в базе. Пример: Вокалоиды.
- Нейронный — ИИ обучается на большой базе данных и старается ей подражать. Пример: воссозданный голос певицы Хибари Мисора.
Догадались что использовали? Тогда давайте сверим результаты. Ответ находится в следующих словах из приведённой выше статьи
Что же делать? Если нельзя синтезировать живую речь с нуля, нужно взять крошечные фрагменты речи человека и собрать из них любую произвольную фразу. Напомню, что в этом суть конкатенативного синтеза
Да, использовался компилятивный синтез. Вот как эти два типа синтеза совмещали:
- Благодаря нейропараметрическому синтезу, с нуля генерируется речь. Полученный результат довольно плохого качества, но для своих целей вполне приемлем.
- Алгоритм ищет в базе кусочков аудио те, которые максимально близко будут подходить к аудио сгенерированному в первом пункте.
Подобный метод в те года применялся и другими голосовыми ассистентами, будь то Alexa или Siri.
Но постепенно все они перешли на технологии на основе трансформеров.
Пользуетесь ли вы голосовыми ассистентами
2017: Трансформеры, объединяйтесь!
Что вы знаете о трансформерах? Если ответили, что их поставил Майкл Бэй, и вы не видите связи с темой статьи, то вы сильно ошибаетесь. Именно трансформеры поспособствовали скачкообразному росту нейросетей, включая и ChatGPT. Речь, конечно же, не о автоботах, а об особой архитектуре глубоких нейронных сетей, которая определила их дальнейшее развитие. Но что они вообще из себя представляют?

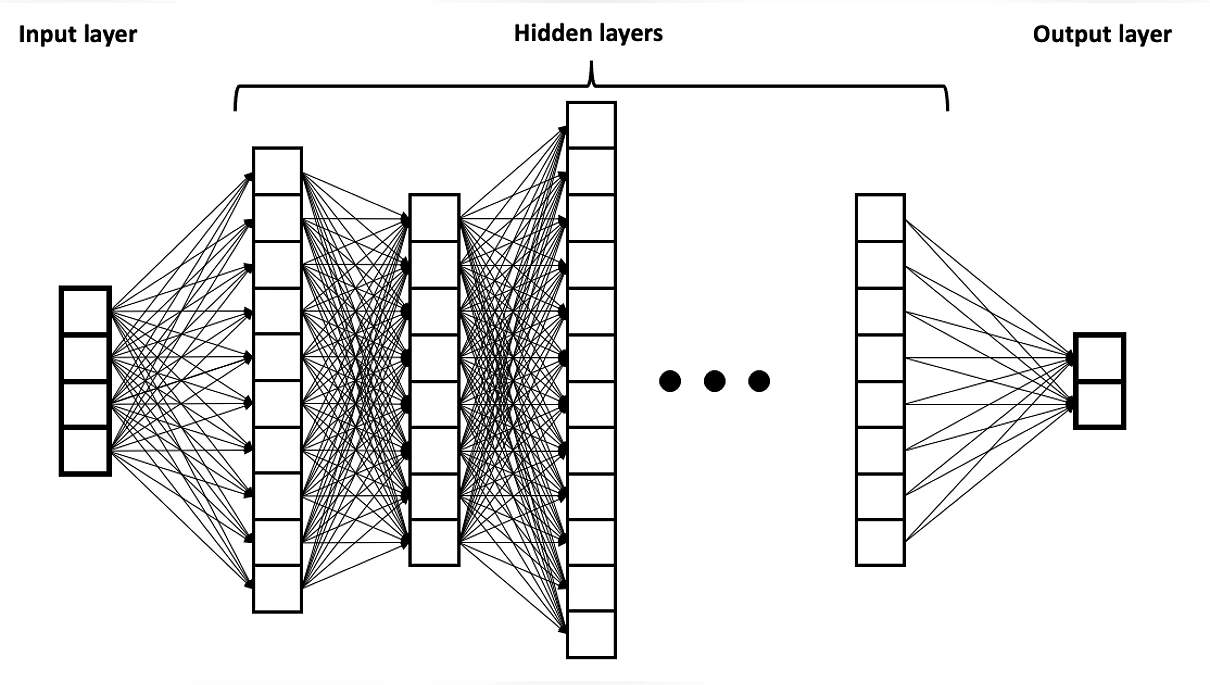
Для начала разберёмся с понятием глубокая нейронная сеть (DNN — Deep neural network). Когда я затрагивал NetTalk, показывал картинку с одним скрытым слоем, а вот у глубоких нейросетей слоёв в десятки и сотни раз больше.
До 2017 года большинство нейросетей обрабатывали крайне маленький объём данных за раз, так как вычисления проходили последовательно, а не параллельно. Это можно сравнить с тем, как вы читаете этот текст. Вы не можете одновременно читать и начало абзаца, и его конец, ведь даже если бы это было осуществимо, можете потерять нить повествования. Забыл упомянуть, что ситуация усугубляется тяжёлой стадией Альцгеймера, из-за которого, читая этот абзац, начисто забываете, что было в предыдущем. Так и с нейросетями. Они не могли начать обрабатывать следующее вычисление, не зная результата предыдущего, да и особой памятью не обладали, из-за чего возникали проблемы с контекстом.
Но всё изменилось в 2017 году, когда 8 исследователей из Google выпустили научную статью, под названием.... прежде чем продолжу хочу чтоб вы были предельно внимательны. Запомните: всё что вам нужно, это — внимание.
Теперь, когда с этими тонкостями разобрались, можем продолжить рассказ об Алисе... Что вы говорите? Не упомянул название? Как?! Я его сказал, просто вы были невнимательны. Да, научная статья называлась «Attention Is All You Need», что являлось отсылкой на песню «All You Need Is Love» группы The Beatles (ох уж эти айтишники. Любят они отсылки везде вставлять. Гвидо ван Россум, автор Python, подтвердит).
Что же такого прорывного было в этой статье? В ней была представлена новая архитектура, трансформер, которая могла одновременно работать с очень большим объёмом сразу. Она основана на технологии внимания (attention) которая была представлена в одной работе 2014 года. Что бы было более понятно как оно работает, вернёмся к примеру с чтением. Если очень упростить, то если раньше вы читали последовательно и для прочтения статьи уходило пару часов, то теперь можете за меньшее время параллельно читать все слова во всех частях этой серии и при этом вы запомните и поймёте всё о чём я писал (и даже то, о чём не писал, но об этом поговорим как-нибудь потом).
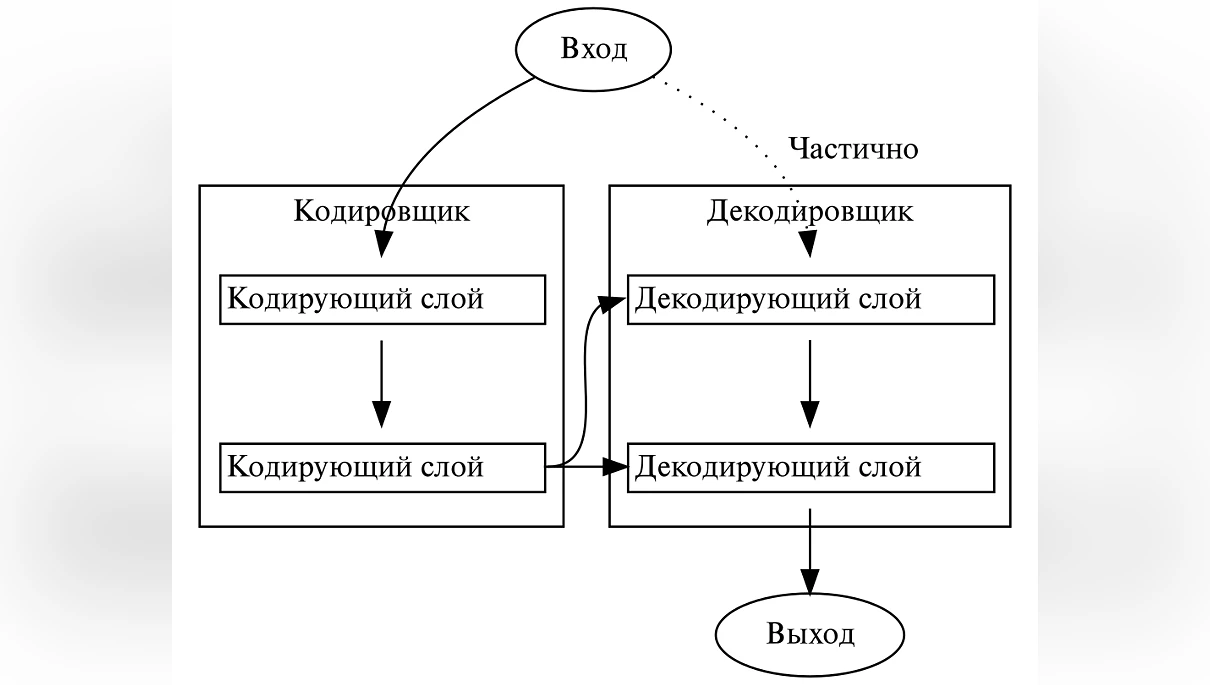
Более подробно обо всём этом можете прочесть в детальной статье Wired или в её пересказе у Forbes. А чтоб подвести итоги этого блока, упомяну о том, что большинство людей которые работали над статьёй, ушли из Google и сейчас работают в области трансформеров в других компаниях или же основали собственные). Примечательно что один из них перешёл к OpenAI и работает над Q*, прототипом общего искусственного интеллекта (AGI), но это тема для другой статьи.
Технология трансформеров позволила значительно удешевить и расширить возможности нейросетевого синтеза. Первым официальным продуктом где были внедрены трансформеры стал Гугл Переводчик в 2018 году. Та же Яндекс Алиса перешла на эту технологию гораздо позже, приблизительно в 2023. А сейчас умный ассистент полностью перешёл на YandexGPT. Нет, название — не калька с ChatGPT (Ну, по большей части). GPT расшифровывается как Generative pre-trained transformer или Генеративный предобученный трансформер. Это означает что модель заранее обучают на большом объёме данных на основе которых и происходит дальнейшая генерация.
Но помимо изобретения трансформеров, 2017 прославился и другим значимым событием, но об этом поговорим в следующей статье.
Итоги
Мы разобрали зарождение нейросетевого синтеза и то, насколько по-разному его использовали. В следующей части затронем тему WaveNet, поговорим о том, как площадка по созданию музыки украла голоса исполнителей и как ваш голос могут клонировать.
Вы, наверное, могли спросить, а где же, собственно говоря, ужасы, заявленные в заголовке? На то время нейросетевой синтез только зарождался, из-за чего был слишком примитивным и доступным лишь узкому числу людей. Поэтому и конфликтов на этой почве не было, а угрозы были чисто гипотетические.
Например, в этом исследовании говорится о повышенной вероятности спуфинга систем голосовой верификации с использованием HMM-моделей. Но с развитием технологий синтеза и доступности нейронок угрозы из теоретической плоскости перешли в реальность. Но об этом мы поговорим в следующей части.
Послесловие
Наконец-то дописал!!! Эта часть далась куда сложнее других. Мой гуманитарный мозг отказывался понимать техническую информацию. Оказалось, что ранние нейронки были по-настоящему колоссальными проектами, требовавшими много времени, сил и изобретательности. Надеюсь, вам было интересно читать сей опус. Естественно, далеко не всё, о чём хотел поговорить, удалось затронуть в статье, надеюсь, в следующей части это удастся. Если же заметили, что где-то ошибся или что-то не учёл, или просто хотите поделиться мнением — пишите об этом в комментариях, с радостью почитаю.
Как вам статья?
Пост создан пользователем
Каждый может создавать посты на VGTimes, это очень просто - попробуйте!-
![]() Представлен Z-Image: мощный ИИ для генерации изображений на домашнем PC
Представлен Z-Image: мощный ИИ для генерации изображений на домашнем PC -
![]() ИИ учится «видеть» глазами человека: в Японии декодируют зрительные образы по активности мозга
ИИ учится «видеть» глазами человека: в Японии декодируют зрительные образы по активности мозга -
![]() ТОП-40 лучших игр про выживание на PC
ТОП-40 лучших игр про выживание на PC -
![]() ТОП-30 самых сложных игр — вам будет больно
ТОП-30 самых сложных игр — вам будет больно -
![]() ТОП-70 игр в открытом мире. Вам точно будет, чем заняться
ТОП-70 игр в открытом мире. Вам точно будет, чем заняться -
![]() ТОП-205: лучшие кооперативные игры в 2025 году
ТОП-205: лучшие кооперативные игры в 2025 году -
![]() ТОП-20: лучшие кооперативные хорроры (2021-2025)
ТОП-20: лучшие кооперативные хорроры (2021-2025) -
![]() ТОП-30: лучшие кооперативные игры для PS4 и PS5 — во что поиграть с друзьями на одной консоли
ТОП-30: лучшие кооперативные игры для PS4 и PS5 — во что поиграть с друзьями на одной консоли -
![]() Лучшие мобильные игры для двоих на iOS и Android (на 2025 год)
Лучшие мобильные игры для двоих на iOS и Android (на 2025 год)








