

С помощью технологии распознавания речи люди преобразуют голос в текст, общаются с колонками и управляют умным домом. Но как это всё устроено по ту сторону интерфейса и какие риски оно в себе таит? В этой статье обсудим, как технология распознавания голоса может не только помогать, но и вредить (даже тем, кто ею ни разу не пользовался).
Как следует из названия, это пятая часть серии статей, посвящённой недобросовестному использованию ИИ. С остальными можете ознакомиться по ссылкам ниже:
Все «Ужасы нейронных сетей»
- Ужасы нейронных сетей. Часть 1: Нейросети и авторское право
- Ужасы нейронных сетей. Часть 2: На каких ваших данных обучаются нейросети
- Ужасы нейронных сетей. Часть 3: Как сделать шапочку из фольги или стоит ли опасаться ИИ?
- Ужасы нейронных сетей. Часть 4: Генерация и распознавание лиц
- Ужасы нейронных сетей. Часть 4.5: Clearview AI и ложные обвинения
- Ужасы нейронных сетей. Часть 5: Распознавание речи
- Ужасы нейронных сетей. Часть 6: Типы синтеза речи. От Стивена Хокинга до Хатсуне Мику
- Ужасы нейронных сетей. Часть 7: История нейросетевой генерация речи. Часть 1: От поющего IBM до разговорчивой Алисы
В 4-й части я подробно рассказал о том, как работает распознавание лиц и как эта технология применяется в ряде стран. Обязательно вернусь к этой теме чуть позже, но пока далеко не ушёл, хотел бы поговорить и о распознавании другого типа биометрических данных — голоса.
А я вас слышу
Представьте, что вы куда-то спешите. Времени мало, но нужно написать длинное сообщение. Набирать вручную слишком долго, а позвонить нет возможности. Что в таком случае делать? Как вариант, записать голосовое. Однако собеседнику может быть неудобно его прослушать. В таком случае на помощь приходит функция голосового ввода, основанная на технологии автоматического распознавания речи или ASR (Automatic Speech Recognition). Она преобразует вашу речь в текст. И собеседник скажет спасибо (хотя не скажет. Он не будет знать, от чего вы его уберегли), и в случае чего можно отредактировать получившийся текст перед отправкой.
Также голосовой ввод применяется для взаимодействия с виртуальными ассистентами по типу Siri, Alexa или Google Assistant. Они могут поставить таймер, позвонить по телефону, создать напоминание, обучиться на ваших данных, слить услышанное куда не надо и множество других полезных штук. Если что, последнее — не конспирологические домыслы, а вполне реальный сценарий.

Так, в этом году (2025 для людей из будущего) Apple выплатила $95 млн вследствие коллективного иска. Истцы утверждали, что виртуальный помощник Siri активировалась без ключевой фразы, записывала разговоры и передавала их рекламодателям. Среди записей была и конфиденциальная информация, включая медицинские данные. Записи собирались вплоть до октября 2019 года, после чего Apple сделала участие в программе добровольным. К слову, подобные инциденты, но без исков, были и у других компаний, включая Google (пару примеров приводил в третьей части).
Распознавание речи есть и в чат-ботах. Например, функция «диктовать» в ChatGPT преображает ваш голос в текстовый запрос с расстановкой знаков препинания.
Как выяснили в прошлых статьях, нейросети учатся на ваших данных, но в случае с ChatGPT ему можно запретить это делать (по крайней мере, так заявляет сама OpenAI). Для того чтоб мало кто нашёл эту функцию, она названа не совсем понятно: «Улучшить модель для всех». Расположена она в Настройки → Элементы управления данными → Улучшить модель для всех.
Но как алгоритм понимает, что вы говорите? Давайте разбираться.
Как упоминалось в предыдущих частях, нейросети учатся на наборе данных с текстовым пояснением к нему. Но в случае со звуком есть свои нюансы. Так же как картинка состоит из пикселей, речь состоит из фонем, отдельных звуков, из которых строится слово. Нейросеть берёт аудио с его текстовым разбором, переваривает в понятную ей конструкцию (чаще всего в мел-спектрограмму), зачастую чистит от шумов, режет на фреймы (короткие отрывки по 10-25 мс) и ищет в них фонемы. Но так обучали модели раньше.
Сложность заключалась в необходимости чётко обозначать, в какой фрейм был произнесён тот или иной звук. Это занятие муторное, долгое и неблагодарное. К тому же разные люди произносят слова по-разному: с разной скоростью, акцентом, чёткостью и т. д. Плюс порой одна и та же фонема может звучать по-иному. Легче накормить нейросетку тонной всевозможных аудио с транскрипциями, и пусть она переваривает себе на здоровье, лишь бы мощностей хватило. Такой подход называется «end-to-end».

Но где найти эту тонну записей?
Обучающий материал можно создать самому или же, как и в случае с распознаванием лиц, найти специальный набор данных, собранный за вас. Откуда собранный? Тут довольно много вариантов.
Обнимашки!
Прежде чем начать, упомяну важный момент при поиске датасетов. А именно то, где их искать. За время ресёрча чаще всего встречались две платформы, Papers with Code и Hugging Face. На первом можно найти базы с различным набором данных, от видео и аудио до графиков и изображений клеток. Но хотел бы разобрать Hugging Face, так как он предоставляет в разы больше материала.
В целом, если очень коротко, то Hugging Face — это «GitHub для ИИ». На нём собрано множество моделей и датасетов, которые можно отфильтровать по предназначению, языку, весу и куче других параметров. Также есть Spaces — платформа для развёртывания систем на базе машинного обучения. Проще говоря, она позволяет запустить модель на серверах Hugging Face, где любой юзер может с ней взаимодействовать. Возможности у представленных моделей самые разнообразные, от генерации картинок до клонирования голоса (более детальнее про синтез поговорю в следующих частях).
В целом довольно удобный инструмент для публикации и поиска необходимых баз. А теперь возвращаемся к базам.
«Наш» датасет
Начать хочу с краудсорсингового проекта Common Voice, основанного Mozilla. Платформа позволяет любому внести свой вклад в развитие общественного набора данных. Это можно сделать несколькими способами: записать заранее подготовленный отрывок, проверить запись другого человека или предложить свой текст для озвучивания. Все собранные данные формируются в датасет под лицензией CC0. (Подробнее о типах лицензий Creative Commons рассказал в первой статье. Ну или просто можете перейти по ссылке на Википедию). Благодаря этому любой может использовать Common Voice для обучения моделей, включая и коммерческие проекты.
Регистрация несложная, и интерфейс интуитивно понятный. Ради интереса проверил около 100 фраз и вот что выяснил. Набор данных очень разнообразный. Есть как зашумленные, с нечётким произношением, так и чистые отрывки, зачитанные с выражением (как будто человек записывал отрывок в перерыве между театральной постановкой и созданием аудиокниги). Пол и возраст тоже разнятся (за всё время услышал только 1 детский голос, но, к сожалению, он допустил грубую ошибку, так что отклонил его вариант).
И в плане лицензий всё хорошо. База пополняется волонтёрами, с других площадок ничего не крадут, заимствуют и предоставляют доступ к датасету всем желающим. Красота!
Вспомнилась недавняя новость (Антимонопольный процесс против Google может уничтожить Firefox), где упоминается, что из-за этого процесса может пострадать и некоммерческие инициативы Mozilla. А они приложили руку к довольно большому числу проектов и исследований, направленных в том числе и на приватность (рекомендую прочесть их статью Accelerating Progress Toward Trustworthy AI). Будет обидно, если эти проекты закроют.
Текст, зачитанный по бумажке, это, конечно, хорошо, но что делать, если хочется более разнообразных данных? Более «живых».
Небольшое отступление
Задумывались ли вы о смерти? Ну, не человеческой, а смерти сайтов, программ, игр и т. д. Сайты закрываются, студии разоряются, а фильмы теряются во времени или считаются таковыми.
Так было с оригинальной украинской дорожкой фильма «За двумя зайцами» 1961 года. Долгое время фонограмма считалась потерянной, но в 2013 году её каким-то чудом удалось найти в мариупольском фильмофонде. Правда, не в самом лучшем техническом состоянии. Умельцы проделали колоссальную работу по улучшению звука и картинки. Со всем списком проведённых манипуляций можно ознакомиться в описании фильма, залитого на Youtube.

Это пример того, когда утраченное наследие удавалось найти. А сколько эпизодов шоу и сериалов навсегда потеряны только из-за того, что пленка считалась ценнее уже записанного материала?
В 70-х годах пленки были дорогими, и проще было перезаписать имеющиеся, чем покупать новые для каждой передачи. Приходит человек на склад, видит пленку с приключениями космического пришельца, путешествующего на телефонной будке сквозь время и пространство, и сражающегося с инопланетной солонкой с венчиком и вантузом вместо рук. Думает: «Эта наркомания точно не станет в будущем популярной» и уничтожает серии «Доктора Кто» ради записи новостей. Хотя в некоторых случаях серии восстанавливали по аудиодорожке и сохранившимся кадрам (а порой и целые эпизоды были спасены благодаря фанатам, которые записывали серию на пленку).
Вот если бы был какой-то архив, сохраняющий файлы и сайты до их потери... О! Так он есть!
Александрийская библиотека ХХI века
Уже более 20 лет работает некоммерческий проект archive.org, на котором собрано огромное количество книг, видео, аудио и программ для разных платформ. Лично я его использовал в ковидные времена, когда нужно было скачать .ipa файлы для iOS7.

А с помощью Wayback Machine можно просматривать раннее состояние сайтов. Просто вставляете ссылку в поле, и отобразятся все сохранённые снимки страницы (если они, конечно, есть). Например, вот так выглядел Youtube в 2013 году.
Снимки полезны, если хочется сохранить какие-то данные до их исчезновения с сайта. Например, эту функцию используют при написании расследований или статей для Википедии. Сайты могут закрыться, удалить/изменить статью, а веб-архив сохраняет то, как выглядела страница в определённую дату.
Я во время подготовки к предыдущей части шерстил веб-архив и в перерывах проходил фанатские карты к шедевральной The Talos Principle. И вот после очередной пройденной головоломки захотелось посмотреть, как выглядел раньше VGTimes.
Стало любопытно, кто их делает, поэтому полез в FAQ. Оказывается, есть несколько способов, один из которых — команда добровольцев, которая этим занимается, Archive Team. Её цель — сохранить интернет-наследие, оставленное людьми.
Один из разделов на портале Archive Team — перечень сайтов, которые закрыты/скоро закроются. Из любопытства нажал на один адрес из списка, который закрылся в 2024 году. Это оказался, судя по всему, довольно значимый ресурс АnandTech, который с 97 года освещал события из мира электроники и комплектующих.
На нём в закрепе висит финальный пост о закрытии, в котором главный редактор, проработавший там 19 лет, благодарит многих людей за помощь и поддержку, делится мыслями и подводит итоги. В нём упоминается, что их издатель будет поддерживать сайт ещё неопределённое количество времени, чтобы люди могли читать те тысячи статей, которые были написаны за эти годы. На этом моменте почувствовал The Talos Principle experience.
Так вот, для чего было это длинное вступление? Чтобы показать масштаб проекта. В заголовке сравнил с Александрийской библиотекой не для красного словца (хотя и для него тоже).
И вот представьте, что есть много данных, удобно структурированных в большие наборы, да ещё и с возможностью всё это добро скачать. Что будет делать человек, который хочет натренировать свою модель? Правильно, «пришёл, увидел, обучил».
Отголоски прошлого
Датасет, о котором пойдёт речь, это Unsupervised People's Speech: A Massive Multilingual Audio Dataset. Набор данных считается одним из самых больших и включает более миллиона часов аудио, взятых с Archive.org. В этом наборе нет транскрипций речи, только аннотации насчёт лицензий (CC-BY-SA и CC-BY 4-й версии). Также при помощи Silero VAD была сделана разметка участков, в которых был обнаружен голос, и прогноз языка каждого аудио, сделанный с помощью Whisper Large V3. Большинство файлов идут от 3 до 10 минут, но некоторые (14) превышают отметку в 100 часов.
Сбереги свой голос
В 2021 году Сбербанк выпустил датасет Golos и открыл его для всех желающих. Часть набора состоит из записей, сделанных на краудсорсинговой платформе (принцип работы схож с Common Voice), а другая часть состоит из данных, записанных на студии и приближённых к реальному применению. Так сказать, «в полевых условиях». Звук записывался на устройство SberPortal с разного расстояния, а сами предложения имитировали запросы к умным устройствам. Лицензия является близкой к CC Attribution ShareAlike, но ею не являющейся (ссылка ведёт на текст лицензии набора). Более подробно можно прочесть в статье на Хабре, написанной одним из создателей «Голоса».
В вышеприведённом примере данные собирались с согласия пользователей, и они об этом явно знали. Но есть датасет, с которым всё туманнее. А именно SOVA DataSet. Это открытый набор данных, содержащий в себе английскую и русскую речь. Набор поделён на части, взятые из разных источников. Например, RuYoutube содержит записи с партнёрских YouTube-каналов, а RuAudiobooksDevices — аудиокниги, записанные на непрофессиональную аппаратуру. Они собирались при сотрудничестве с авторами, и к ним вопросов нет. Но меня привлекла часть под названием RuDevices.
Нашёл я её, когда шерстил HuggingFace на предмет датасетов подозрительного происхождения. На портале можно прослушать примеры речи, и что-то они не похожи на то, что могло быть собрано с добровольного согласия. Они скорее похожи на обрывки голосовых сообщений: во многих есть мат, речь живая, посторонние звуки на заднем плане и т. д.
Полез узнавать, как был собран этот набор. Свет на ситуацию пролила запись в блоге «Совы». В нём компания даёт полезные советы тем, кто хочет обучить свою сеть, и рассказывает, с чем ей пришлось столкнуться на этом пути. В частности, упоминается, что для того, чтоб модель лучше справлялась, требуется обучать её на данных, схожих с конечной задачей.
Так как SOVA предоставляет чат-ботов для колл-центров, то и обучать её требовалось на данных телефонных звонков и краудсорсинга типа «Толоки» (но не на ней, так как не желали делиться данными клиентов с Яндексом + хотели иметь обратную связь с теми, кто будет работать с записями). Но где найти записи телефонных разговоров? Они сотрудничали с колл-центрами и бесплатно давали пользоваться продуктом в обмен на данные для обучения.

Также у них есть телеграм-бот @voicybot, который переводит голосовые сообщения в текст. Бота можно добавить в чаты и настроить. Хоть на ГитХабе лежит его исходный код и на сайте бота говорится, что данные на серверах не хранятся, но:
1. Бот шлёт ссылку на политику конфиденциальности, расположенную на сайте разработчика. Утверждается, что эта политика едина для всех проектов автора, а значит, и бота тоже касается. В ней значится, что личная информация собирается для «предоставления и улучшения Сервисов». Причём полного перечня того, что считается «личной информацией», нет. Т. е. можно предположить, что они используют аудио, отправленные в бот, для кормёжки модели.
2. В комментариях к блогу сами авторы прямым текстом об этом упоминают.
...мы собирали свой [датасет] с помощью компаний партнёров из колл-центров и бота Voicy.
К слову, это был ответ автору другого крупного датасета, Open STT.
В этом наборе привлекло внимание часть с телефонными звонками. Прослушав более 50 записей, стало ясно, что в нём использовались записи пранков, издевательств над людьми. Кто-то звонил в госорганы, такие как военкоматы, и под разными предлогами старался вывести собеседника из себя. В частности, много раз упоминался 314 кабинет (как потом выяснилось, это довольно популярная серия пранков, издевательств).
Стало любопытно, откуда взяты эти данные. Поиски привели меня в блог одного из разработчиков. В нём он разбирал критику в отношении ASR-моделей и давал советы начинающим авторам. В частности, разбирался тезис «Создание продакшен-решений на основе приватных данных, о чем в самих публикациях информации очень мало». Позже в статье автор признаётся, что и их компания подобным грешит.
Мы использовали приватные данные для тренировки своих моделей, хотя размер нашего приватного датасета меньше полного размера датасета на порядок.
Далее приводится список источников аудио, среди которых: «пранки», различные звонки (такси, бронирование, коммерция и т. д.), YouTube и аудиокниги. Последние два хочу рассмотреть подробнее.
Из ответов на комментарии под другим постом становится ясно, что книги были легально скачаны по абонементу. Правда, насчёт YouTube-роликов всё туманно. Авторы уверены, что используют контент по принципу Fair use (добросовестное использование) и, так как распространяют его бесплатно, ничего не нарушают. Вот ответ одного из авторов, написанный другому пользователю (который тоже обеспокоился вопросом легальности сбора некоторых данных). Советую прочесть всю ветку, там довольно много интересного.
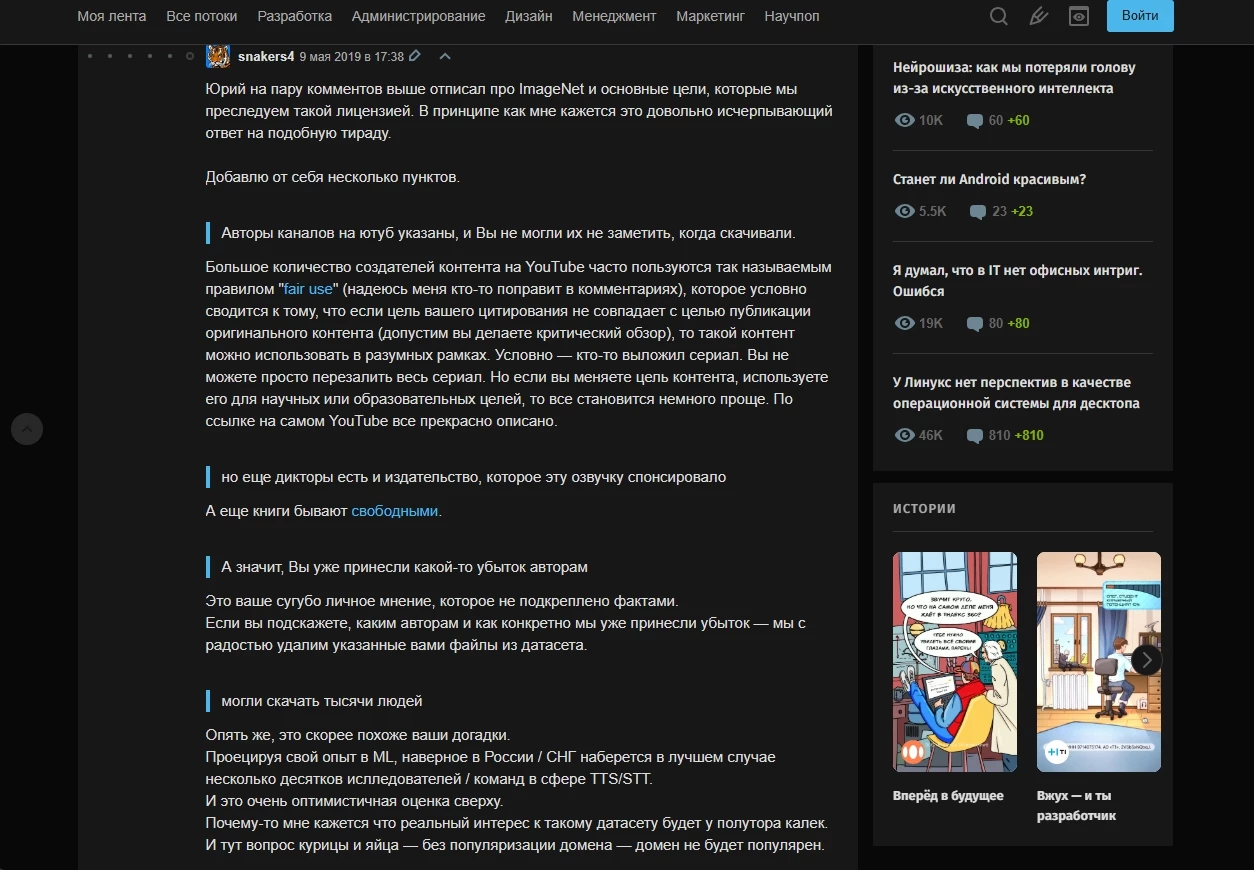
Мы знаем, что мы можем ненароком нарушить чьи-то права. Но не знаем, как массово опросить авторов, не нарушили ли мы этого случайно. И, кстати, мы в одной лодке с Youtube, Facebook, Habrahabr и другими организациями, которые выкладывают контент пользователей, не проверив, какие есть у пользователей права на контент, но имеют процедуру отзыва нелегально полученного контента.Кроме того, книги были скачаны мной легально по абонементу интернет-библиотеки.На авторское право мы не претендуем, книги не читаем, читать и слушать аудио пользователям не даём (данные нарезаны на фрагменты и раскиданы по хешам — как документы после шрёдера), считаем, что убытков никому не наносим.Гарантий на данные мы не даём. Мы предлагаем эти данные для использования по fair use (см. коммент выше от snakers4), для научных, исследовательских и образовательных целей или же чтобы пользователи использовали их на свой риск, в том числе сами убеждались в наличии необходимых лицензионных соглашений на нужное им использование. Мы явно об этом говорим.Мы не зарабатываем на данных, но потенциально допускаем возможность заработать на датасете, и лишь если в случае, если кто-то другой на нём зарабатывает деньги (про другие цели лицензии на «коммерческое использование» я выше в ветке написал), все тексты и аудио пользователи могут скачать и сами без нас.Я был бы рад, если бы существовала процедура массово связаться с правообладателями и спросить их явное разрешение на наше нестандартное использование. Мне кажется, многие будут за. Но выискивать каждого автора в интернете самим у нас сил не хватит. Если у вас есть предложения, как это легко можно сделать — пишите.Вот у меня есть канал на YouTube — но как там со мной связаться?
Но лично у меня такой подход вызывает вопросы. Документы после шредера всё равно можно восстановить, записей это тоже касается. И то, что любой другой может скачать эти данные, не отменяет факта, что это с трудом можно назвать добросовестным использованием. Хотя если аудио аннотированы и чуть переработаны для более эффективного скармливания нейросети, то с очень большой натяжкой может подпадать под fair use. Но в таком случае всё равно остаются вопросы к отрывкам из «пранков»... Сомнительно, но окей.
Ещё много есть что сказать касательно датасетов, но пост не резиновый (хотя вообще-то резиновый, но полотно текста вряд ли кто читать будет). Главное, мы разобрались, откуда получают учебный материал.
В начале статьи упоминал разные варианты использования ASR, теперь хочу поговорить о происшествиях, которые с ними связанны.
Алекса, купи слона
Бывало ли такое, что ваш голосовой помощник включался от постороннего голоса (будь то другой человек или ролик на YouTube)? Нет? Ну и ладно. А вот у кого-то бывало.
Как уже упоминал, виртуальные ассистенты могут приносить пользу. С их помощью можно ставить напоминания, совершать звонки и даже управлять умным домом. Но ещё они могут совершать покупки. В большинстве ассистентов, помимо голосовой команды, нужно подтверждать покупку иным способом (кнопка «подтвердить», пин-код или нечто подобное). Однако не во всех ИИ-помощниках это является обязательным. Например, Amazon Alexa позволяет совершать заказы даже без подтверждения. Вот как это выглядит на практике.
![Ordering Items Through Amazon Echo (Alexa) [Using your voice to shop]](https://i.ytimg.com/vi_webp/jJopb09ieV8/sddefault.webp)
В ролике человек просит Алексу заказать ручку, и после уточняющего вопроса заказ оформляется. Это вызывает опасения, связанные с ложным срабатыванием. Девайсу может не то послышаться, из-за чего закажет ненужную вещь (при условии, что к нему привязана банковская карта и известен адрес доставки). Иронично, что сам Amazon шутил на эту тему в одном из своих роликов.

К сожалению реальные случаи тоже были.
Так, в начале 2017 года шестилетний ребёнок, играя с Amazon Alexa, случайно заказал кукольный домик Kidkraft за 170 долларов и около 2 килограмм печенья. Сам ребёнок отрицал, что просил у устройства совершить покупку, но упомянул, что расспрашивал Алексу про кукольный домик и печенье. Возможно, бот неправильно понял запрос.
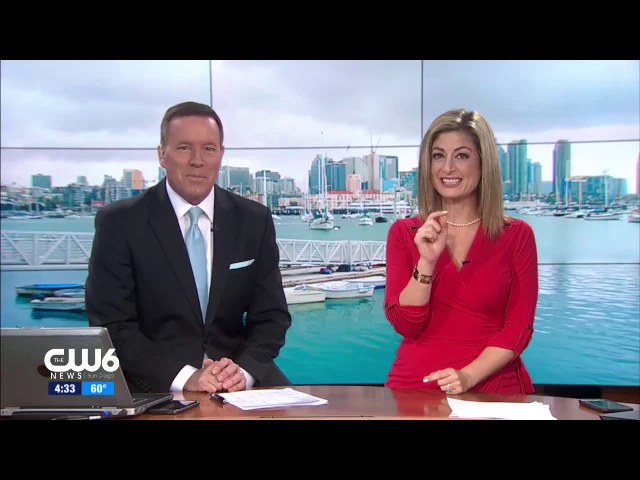
Самое интересное случилось, когда об этом узнали новости. В репортаже CW6 ведущий сказал фразу «Alexa ordered me a dollhouse», после чего, как утверждается в нижеприведённом ролике, жители по всему Сан-Диего столкнулись с непреднамеренными заказами кукольных домиков.
Чтобы такого не происходило, важно ставить дополнительные меры предосторожности. Впрочем, в большинстве помощников они и так по умолчанию включены, так что это не такая уж массовая проблема (хотя парочка других случаев есть тут и тут). А как быть с другой функцией, которая не требует подтверждения?
Сам себе сваттер
С помощью ассистентов можно звонить не только знакомым, но и в службы спасения. Хотя некоторые устройства такие звонки не поддерживают (как, например, станции Alexa, из-за особенностей закона касательно VOIP-телефонии), но другие это позволяют делать.
Например, на «Реддите» был пост о случайном звонке в полицию. По словам пользователя, он смотрел записи с видеорегистраторов на YouTube, и в видео был момент, когда водитель чётко произнёс «OK Google. Call 911» и его телефон, лежащий рядом, начал звонить на сказанный номер. Он успел сбросить звонок, но просил совета насчёт дальнейших действий. Также к посту было прикреплено видео, которое он смотрел.

Таймкод фразы: 7:44
Но это пост с «Реддита»... Без каких-то доказательств... Вот если бы был задокументированный случай, тогда да... А он есть.
Это произошло в 2023 году с Джейми Аллейном (Jamie Alleyne). 34-летний спортивный тренер, занимался с клиентом в зале боевых искусств PTJ Gladesville. Он был ошарашен, когда к спортзалу подъехали около 15 полицейских и пара машин скорой помощи. Стражи правопорядка утверждали, что получили сообщение о выстрелах.

Выяснилось, что виной всему была Siri, установленная на Apple Watch тренера. Джейми случайно её активировал, пока занимался с клиентом. В это время Джейми несколько раз выкрикивал «1-1-2» (что является альтернативным номером экстренных служб) и подбадривал клиента, произнося «good shot». Скорее всего, оператор услышал звуки ударов и крики и, решив, что там идёт стрельба, вызвал медиков и полицию.
Прибывшие полицейские с пониманием отнеслись к ситуации, а сам тренер стал отключать Siri во время занятий.
Заключение
В завершение хочу сказать, что, несмотря на столько негативных случаев, такие системы действительно могут спасти жизнь. К примеру, с помощью функции SOS в Apple Watch, один мужчина, которого унесло на более чем 1,5 км от берега, смог вызвать спасателей. Apple даже об этом ролик сняла.

Как и говорил, это технология. И, как и любая технология, она может нести как пользу, так и вред. А вот перекрывают ли плюсы их использования минусы — каждый человек решает сам.
Послесловие
Вот и подошла к концу моя статья. Изначально планировал затронуть и синтез, и распознавание речи, но слишком много материала откопал. Всегда рад фидбеку в комментариях. Если что-то не так осветил — поправьте.
Понравилась ли вам статья? Делитесь мнением в комментариях!
А на этом у меня всё. Увидимся в следующей статье!


