
Ужасы нейронных сетей. Часть 6: Типы синтеза речи. От Стивена Хокинга до Хатсуне Мику
 ithitym
ithitym
Наверняка вы не один раз слышали синтезированный голос. Его используют в навигаторах, автоответчиках, для объявления остановок и т.д. Мы настолько часто его слышим, что уже воспринимаем как само собой разумеющееся. А интересно, как это всё работает? В этой статье я простыми словами расскажу о типах синтеза речи и способах его применения.
Эта статья — часть цикла который посвящён моей нейро-паранойи. С остальными можете ознакомиться по ссылкам ниже:
Все «Ужасы нейронных сетей»
- Ужасы нейронных сетей. Часть 1: Нейросети и авторское право
- Ужасы нейронных сетей. Часть 2: На каких ваших данных обучаются нейросети
- Ужасы нейронных сетей. Часть 3: Как сделать шапочку из фольги или стоит ли опасаться ИИ?
- Ужасы нейронных сетей. Часть 4: Генерация и распознавание лиц
- Ужасы нейронных сетей. Часть 4.5: Clearview AI и ложные обвинения
- Ужасы нейронных сетей. Часть 5: Распознавание речи
- Ужасы нейронных сетей. Часть 6: Типы синтеза речи. От Стивена Хокинга до Хатсуне Мику
- Ужасы нейронных сетей. Часть 7: История нейросетевой генерация речи. Часть 1: От поющего IBM до разговорчивой Алисы
Как мы узнали из предыдущей части, распознавание голоса может нести свои риски. Но зачастую эта технология идёт в связке с синтезом речи, о котором и пойдёт речь в этой статье.
Синтез речи — это восстановление формы речевого сигнала по его параметрам. Звучит максимально сухо, но именно такая формулировка позволяет понять, как этот синтез происходит.
За последнее время эта область сделала довольно большой скачок вперёд. До сих пор помню, как удивлялся, когда слышал живой голос Яндекс Алисы. Но время шло, технологии улучшались, и теперь синтезировать голос может любой человек, используя готовые библиотеки. Но как эта технология работает? Давайте разбираться.
Хоть в названии есть слово «ужасы», начать хочу с того, что действительно многим приносит пользу, а именно помощь людям с ограниченными возможностями. На самом деле, это одна из немногих вещей, которые мне нравятся в искусственном интеллекте.
Не так давно прочёл великолепную манхву «Не вижу, не слышу, но люблю» про ослепшего из-за переутомления автора манги и глухую девушку. Произведение невероятно трогательное и столь же печальное. Оно подтолкнуло на размышления о том, как воспринимают мир те, кто ощущает его по-другому.
Мы воспринимаем слух, обоняние, речь и способность видеть как само собой разумеющееся, в то время как другой многое бы отдал лишь за возможность ещё раз увидеть лица родных. Но, к счастью, прогресс не стоит на месте, и сейчас есть довольно много функций, которые помогают людям вернуть утраченные способности (или, по крайней мере, заменить на нечто похожее).
Начну, пожалуй, с самого известного применения синтеза речи.
Вселенная Стивена
В 1963 году, когда Хокингу был 21 год, у него обнаружили боковой амиотрофический склероз (БАС). Это заболевание медленно убивает двигательные нейроны, постепенно парализуя инфицированного. Врачи давали неутешительные прогнозы. По их словам, пройдёт всего пара лет, прежде чем болезнь поразит дыхательные пути, из-за чего больной не сможет самостоятельно дышать и питаться. При этом в его случае на когнитивные способности хворь никак не сказывается. Т.е. абсолютно ясный ум становится заперт в парализованном теле. У этого явления даже название есть: Синдром запертого человека.
Хокинга это сильно подкосило. Молодой парень, который думал, что у него вся жизнь впереди, вдруг узнаёт, что у него осталось очень мало времени. К счастью, болезнь прогрессировала медленнее, чем предсказывали. Так что он продолжил заниматься своим любимым делом, физикой и космосом. В частности, его заинтересовали чёрные дыры.
Первые пару лет он мог ходить, опираясь на трость, но позже болезнь приковала его к коляске. Несмотря на это, он оставался жизнерадостной личностью, с которой было приятно общаться. Даже будучи в коляске, Стивен Хокинг умудрялся лихо рассекать по территории университета, из-за чего получал предупреждения.
Ходили слухи, что он специально наезжал на ноги тех, кто ему не нравился, включая принца Чарльза. Впрочем, сам «гонщик» опровергал это утверждение, заявляя: «Это злонамеренный слух. Я перееду любого, кто его повторит».
Его биография довольно интересна, и хотелось бы о нём написать ещё больше, но, к сожалению, тема статьи не сам учёный, а его коляска и установленные на ней приспособления. А что касается его истории, рекомендую посмотреть это видео.

Я же хочу остановиться на системе, с помощью которой он мог говорить, будучи почти полностью парализованным.
В 1985 году во время поездки в ЦЕРН Хокинг заболел пневмонией. Болезнь для ослабшего тела была настолько серьёзной, что его подключали к ИВЛ, а сами медики не считали, что он пойдёт на поправку. Страшно представить, что чувствовала его жена, когда врачи предложили ей отключить мужа от аппарата. К счастью, он выкарабкался, но потерял возможность говорить из-за проведённой трахеотомии (когда в горло вставляют трубку, чтоб человек мог дышать).
Поначалу для общения Хокинг использовал орфографическую карту, указывая на буквы с помощью поднятия бровей. Но этот способ был утомительным и малоэффективным, поэтому вскоре его заменили на специальное ПО Equalizer, работавшее на Apple II, в связке с синтезатором речи от Speech Plus. Позже эту систему сделали переносной и адаптировали под коляску.
Со временем он поменял программу на EZ Keys с ручным переключателем. Таким образом, учёный при помощи кликера мог «печатать» со скоростью 10–15 слов в минуту, после чего синтезатор преобразовывал текст в голос. Благодаря этому он даже мог выступать с лекциями. Стивен заранее подготавливал материал, разбивал на абзацы, а после зачитывал его своим новым голосом.

«Человек не только хочет, чтобы его понимали, но и не хочет звучать как Микки Маус или далек»
В 1997 году Хокинг познакомился с соучредителем Intel Гордоном Муром. Мур заметил, что учёный использует систему на базе процессора AMD 486, и в шутку спросил, не хочет ли тот перейти на «настоящий компьютер», работающий на процессоре от Intel. Таким образом, Intel взяла на себя заботу за обеспечение профессора новейшими разработками и обновляла его компьютер каждые пару лет.
К слову, на сайте Intel есть об этом заметка, датированная 1997 годом.
Единственное, что инженеры не трогали, это плату синтезатора речи Speech Plus CallText5010, разработанную ещё в конце 80-х (позже Хокинг перешёл на эмулятор, работающий на Raspberry Pi), и ПО EZ Keys (которое улучшали по возможности). Хокинг с 80-х использовал встроенный в Speech Plus CallText5000 синтезированный голос под названием Perfect Paul. За столько лет он к нему так прикипел, что, когда появились новые синтезаторы, позволяющие «говорить» менее роботизированным голосом, он оставил свой «родной». Для этого плату CallText5010 модернизировали, добавив в него голос из прежней версии, 5000. Таким образом, «Perfect Paul» стал ассоциироваться с гениальным учёным. Уникальный случай, когда синтезированный голос стал нераздельной частью реального человека.
К слову, плата Speech Plus CallText5000, принадлежащая Хокингу, выставлена в музее, где её можно рассмотреть со всех сторон.

В 2008 году болезнь ослабила работающую руку настолько, что Хокинг больше не мог использовать её для управления синтезатором, поэтому его ассистент разработал «щечной переключатель». Устройство прикреплялось к очкам и с помощью направленного вниз инфракрасного луча могло улавливать напряжение мышцы щеки. С тех пор он мог сёрфить в интернете, проводить лекции и писать письма и книги, используя только этот щечной переключатель.
Но со временем его способность «говорить» начала снижаться настолько, что к 2011 году он мог напечатать только пару слов в минуту. Такой расклад его не устраивал, поэтому Хокинг написал письмо Муру и поинтересовался, можно ли это как-то исправить. В ответ к нему приехала команда из Intel Labs, которая начала поиск других вариантов взаимодействия с устройством. EZ Keys хоть и имел базовую систему предсказания слов (она схожа с подсказками слов в клавиатуре телефона), позволял управлять курсором в Windows и сёрфить в интернете через Firefox, но ПО было уже очень древним, так что требовалось что-то новое.
К проблеме подходили с разных сторон. Инженеры пытались прикрутить отслеживание глаз, но мешали низко опущенные веки. Нейроинтерфейс также стал проблемой. Система, идеально работающая с членом команды, не хотела работать на Хокинге. Первые попытки упростить набор текста тоже были неудачными. Но в конечном итоге было найдено решение.
В 2013 году у Хокинга появилась новая система ACAT (Assistive Contextually Aware Toolkit), которая очень упростила его коммуникацию с компьютером и окружающими. В частности, использовали предсказатель слов от SwiftKey, дополнительно обученный на трудах учёного. Это значительно повысило скорость набора текста.

Модернизации подверглась и горячо любимая плата синтезатора речи. Компания, её выпускавшая, закрылась ещё в 90-х, поэтому ни замены, ни запчастей было уже не сыскать. Да и сама система была громоздкой. Поэтому была начата разработка эмулятора синтезатора на основе Raspberry Pi.
Подробно об этом можно прочесть в статье Stephen Hawking's Voice Emulator Project (там же находятся ссылки на другие интересные работы).
Таким образом, по состоянию на 2018 год у Стивена Хокинга была следующая комплектация (перечень взят с его сайта):
- Эмулятор Speech Plus CallText 5010, работающий на Raspberry Pi 3.
- Система ACAT от Intel.
- Особые динамики, разработанные Sound Research.
- Lenovo Yoga 260, Intel Core i7-6600U CPU, 512 GB Solid-State Drive, Windows 10.
- Инвалидная коляска Permobil F3 от Permobil.
- Прочие аппаратные решения от Intel.
Этими устройствами он пользовался вплоть до самой смерти. К сожалению, 14 марта 2018 года болезнь, поставленная полвека назад, всё-таки забрала жизнь гениального учёного. Он умер дома, оставив после себя троих детей.
Чтоб не заканчивать блок на такой грустной ноте, хотел рассказать об одной из его «шалостей».
Стивен был озабочен теорией путешествий во времени. Чтобы расставить всё по местам, он устроил вечеринку для путешественников во времени, но приглашения на неё разослал после её проведения. Мероприятие (было) назначено на 28 июня 2009 года и прошло в гордом одиночестве. Из этого учёный сделал вывод, что путешествия во времени невозможны.
Хотя, как по мне, будь я путешественником во времени, тоже не пошёл бы. Я слишком много смотрел в последнее время «Доктора Кто» и знаю, к чему могут привести манипуляции со временем-шременем. Объясняю. То, что на вечеринку никто не пришёл, могло стать ключевой точкой в истории, благодаря которой могли начаться процессы по созданию таких машин. А если бы кто-то из будущего пришёл на неё, это бы нарушило причинно-следственную связь. Если что, я не путешественник во времени (но от IBM 5100 не отказался бы).

Примечательно, что на церемонию памяти можно было зарегистрироваться всем, кто родился до 31 декабря 2038 года.
И в завершении блока о гениальном человеке (и для того, чтоб опять связать тему с ИИ), приведу его интервью 10-летней давности, в котором Стивен Хокинг выказывал опасения насчёт развития искусственного интеллекта и поделился мнением о своей системе АСАТ. А вот тут часть про ИИ, но с русской озвучкой.

В видео можно услышать голос «Perfect Paul». Для его синтеза применялся формантный метод. Не бойтесь непонятного слова, сейчас всё объясню.
Формантный синтез
Помимо нейросетевого синтеза (он же end-to-end, о котором писал в прошлой части), есть и другие методы генерации речи. В этой статье не смогу всё затронуть, поэтому разберу только некоторые, которые можно встретить в повседневной жизни.
Синтез речи, применяемый в синтезаторе CallText 5000, называется формантным. Если не вдаваться в дебри, то при формантном типе машина математически пытается воссоздать звучание голоса, на котором она была обучена. Например, в вышеназванном синтезаторе за основу «Perfect Paul» были взяты данные, полученные из образцов голоса разработчика, Денниса Х. Клатта (Dennis H. Klatt).
Но как именно в 80-х, без нейросетей и прочего, смогли сделать такой синтез?
В предыдущей части я упоминал про фонемы — наименьшую звуковую единицу в речи (для простоты будем считать их равнозначными буквам). Когда мы произносим какую-то букву, на спектрограмме это может выглядеть как последовательность из всплесков и затуханий звука. Такие всплески называют формантами. Формантные частоты располагаются в диапазоне от 200 до 2000 Гц. Для того чтоб воспроизвести одну фонему, требуется указать несколько формант, зачастую от 2 до 4. Наглядно это можно глянуть в этом коротком ролике или на картинке ниже.
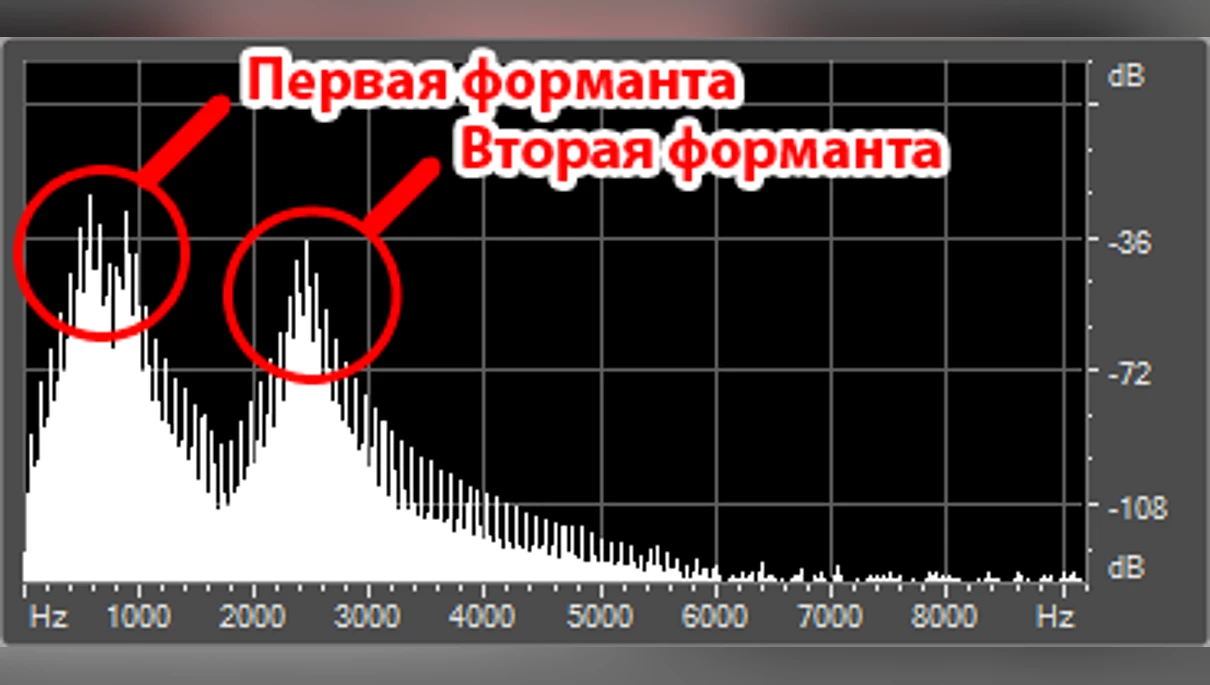
Вот как этот тип синтеза работает. На входе даётся шум, который, проходя через формантные фильтры, приобретает звучание, схожее с голосом. Это можно сравнить с нашей речью. Мы производим звук, который, проходя через сложную речевую систему, речевой тракт (набор фильтров), преобразуется в понятные слова. Это хорошо заметно на примере гласных. Попробуйте на одном дыхании перейти от «а» до «о» и «у». Разные звуки получаются в следствии изменённых «фильтров».
Для наглядности вот примеры значений для пары звуков.

Формантный синтез используют в системах с ограниченной памятью и мощностями, например в телефонных справочниках, музыкальных синтезаторах и устройствах для людей с ограниченными возможностями.
Более подробно про этот метод можно прочесть здесь. Ну а мы движемся дальше.
Обратная связь
Другой пример использования синтеза речи для благих целей есть в большинстве телефонов. Наверняка вы слышали о функции TalkBack в Android, позволяющей работать со смартфоном, даже если человек слабовидящий или полностью слепой. Она предоставляет звуковую информацию о нажатом объекте на экране.

Ради интереса включил и попробовал с закрытыми глазами отключить эту функцию, ориентируясь только на звуковые подсказки. Начинал с главного экрана. Хоть элементы озвучивались без проблем, было сложно ориентироваться в собственном устройстве. Экран казался слишком большим, и постоянно забывал, куда именно кликал. Зато есть звуковое сопровождение при переходе на другие меню, что помогало ориентироваться. Естественно, этот «эксперимент» не идёт ни в какое сравнение с тем, что испытывают реальные люди, использующие TalkBack на постоянной основе.
В отличие от предыдущего примера, в TalkBack нет своего синтезатора. Он использует Text-to-Speech-движок, который вы сами установите. Что такое Text-to-Speech? Это синтез голоса на основе текста. Это не отдельный тип синтеза, а скорее один из способов его применения.
К слову, если вы читаете эту статью с браузера Microsoft Edge, то можете использовать функцию «Прочесть вслух», работающую тоже по принципу TTS. С её помощью сможете превратить длинный текст, как этот, в аудиоподкаст. На выбор предоставлено множество голосов на разных языках, но для русского и украинского голосов мало. Только по одному варианту мужского и женского.

Пример озвучки в Edge
Так о чём я? Ах да! TalkBack!
По умолчанию выбран синтезатор или от Google, или от той же компании, что и само устройство. Например, на стареньком Samsung это «Модуль TTS Samsung». Но вы можете скачать любой другой.
Учтите, что у стороннего синтезатора будет доступ к любому тексту, на который вы кликнете. Т. е. это могут быть пароли, данные банковских карт и прочая информация, отображаемая на дисплее. Ну, таков принцип работы, и ничего не сделаешь, помимо тщательного выбора поставщика TTS. Можете начать поиск с этого поста на «Реддит», где обсудили пару таких приложений.
А я пока остановлюсь на разборе двух из них, которые используют разные подходы к синтезу речи.
Соло на Брайлевском дисплее
То, что внушает больше доверия, это RHVoice — бесплатный синтезатор речи с открытым исходным кодом и без рекламы. Доступен на Linux, Windows и Android. Разработан при активном сотрудничестве с целевой аудиторией. Настолько активном, что сама основательница и по совместительству программист (Ольга Яковлева) является незрячей. Более подробно про это можно послушать на «Тифлостриме» и в этом посте с Хабра: «Как слепой разработчик в одиночку создала синтезатор речи».

На русском и украинском языке доступен довольно широкий выбор голосов приятного качества. На русском больше всего понравились Seva и Artemiy, а на украинском — Marianna и Anatol. Слова произносятся сразу после клика на элемент экрана, без каких-либо задержек.
Ознакомиться с демонстрацией работы можно в этом гайде по установке RHVoise на Linux.

В описании ролика есть текстовая инструкция по установке, включающая команды для терминала
Подробности этого шикарного приложения разберу в другой статье, а пока хочу поговорить о методе синтеза, который в нём использован.
Согласно этой статье на Хабре, тут используется параметрический синтез, работающий со скрытой марковской моделью (СММ). Понапридумывают всяких слов, потом гуманитариям разбираться. Не пугайтесь сложных названий, сейчас всё объясню.
Суть СММ в предсказывании последовательных неизвестных параметров на основе известных. Таким образом, параметрический синтез предсказывает благозвучную последовательность звуков, опираясь на сам текст, знаки препинания и правила построения слов.
К примеру, возьмём слово «лапидарный», которое означает «краткий», «сжатый», «ясный». Мы не знаем, где ставить ударения, но замечаем, что оно благозвучно звучит, если поставить его посередине. Это наблюдение сделали на основе схожих по построению слов (например, «ламинарный»). Также мы знаем, как это слово склонять, хотя никогда его не видели. Так же работает и параметрический синтез речи.
Но как именно он получает образец того, как должен звучать правильный вариант? Пройдусь по шагам его обучения (данные взяты из вышеприведённого поста, в котором затрагиваются этапы создания голосов для RHVoise).
Сбор правил построения слов.
Первым делом нужно собрать фонетическую систему языка. Т. е. правила построения звуков, слов, предложений, интонаций, ударений, список всех звуков и т. д. В отдельных случаях, если язык сложный или малоизученный, такой сбор может занять до полутора лет. К примеру, вот одна из подобных баз на GitHub. Таким образом создаётся анализатор языка, который по имеющимся вводным может разобрать предложение на части.
Подготовка предложений для зачитки.
Теперь нам нужны предложения для последующей зачитки, результат которой будем разбирать с помощью анализатора. Предложения должны быть построены таким образом, чтоб затрагивать все дифоны, т. е. все комбинации переходов между фонемами. Дифоны начинаются в середине одного звука и заканчиваются в середине другого. Предложения можно написать самим, купить уже готовые или скопировать откуда-то ещё (например, авторы языковых моделей RHVoise брали их из Википедии. Хотя такой способ не работает с менее распространёнными голосами из-за малой базы данных).
Создание речевой базы.
Диктор должен чётким и безэмоциональным голосом начитать более тысячи предложений. Стоит отметить, что этот процесс весьма долгий, так как диктор может максимум 4 часа в день зачитывать, не теряя «чистоту» голоса. К качеству таких записей относятся очень придирчиво, дабы получившийся голос не «скакал» по тембру и диапазону. Поэтому компании при выборе диктора делают акцент не только на красивый голос, но и на умение придерживаться определённого тона для конкретного языка.
Анализ речи.
Система (а зачастую и человек) анализирует записанную речь, находит закономерности, вычленяет составные части (тон, тембр, скорость, форманты и т. д.), классифицирует фонемы, их границы, расположение относительно друг друга и прочее. Так у системы появляются представления о правильном произношении фонем, так что сможет сказать даже то слово, которое не входило в обучающую базу. Вернее, сказать ещё не сможет, на данном этапе у модели есть только текст и аудио диктора. Она должна кричать, но у неё нет рта.
Разметка текста и выбор подходящих звуков.
Далее запись разрезается на фрагменты согласно базе данных. Затем анализатор языка соединяет эти фрагменты вместе, опираясь на грамматику, структуру предложения, члены речи, знаки препинания, паузы и т. д. В зависимости от всех этих параметров подбирается максимально близкая по звучанию фонема.
Генерация мел-спектрограммы.
Теперь у нас есть текст для озвучки. В предыдущей статье я упоминал, что при распознавании речи звуки «перевариваются» в мел-спектрограмму, а позже в текст. Тут же происходит обратный процесс. Текст преобразуется в этот особый вид спектрограммы, которая оптимальна для визуализации человеческого голоса.
Синтез речи.
Предпоследний пункт обучения — это непосредственно сам синтез речи. Специальный механизм, вокодер, берёт мел-спектрограмму из предыдущего пункта и преобразует их в речевой сигнал. Таким образом у нас получается конечный звук.
Корректировка.
Заключительной частью является корректировка и исправление неточностей.
Зачастую недостаточно иметь базу с правильным произношением слов. Порой нужна помощь самих носителей языка, чтоб могли подкорректировать некоторые места и объяснить, что и где пошло не так.
Как видим, хоть процесс довольно сложный и с кучей нюансов, зато речь звучит качественнее, чем при формантном синтезе.
Нейронный голос из глубин телефона
Помимо стандартных TTS движков, работающих на параметрическом синтезе, есть и те, которые используют нейронные сети, как, например, sherpa-onnx. Речь генерируется непосредственно на устройстве, и качество звучания весьма хорошее. Но есть в этом огромный минус. На устройствах со слабым процессором между тапом на экран и озвучкой проходит от 2 до 8 секунд. За это время можно и забыть, куда и зачем нажимал. Хотя, может, на современных девайсах такой задержки и нет (скорее всего, так оно и есть). Чуть подробнее про нейронный синтез расскажу ближе к концу поста, а пока вот краткое мнение насчёт голосов этого движка.
В программе доступно 4 русскоязычных голоса. Ирина слишком роботизированно звучит, Денис картавит (и как будто звук с плохого микрофона), Дмитрий вроде сносно говорит, но порой окончания сбоят, а у Руслана «речь» вполне неплохая, но что-то с окончаниями слов неладно, и такое ощущение, что слишком большие паузы между ними делает.
Украинских голосов доступно 2. У Uk_lada-x_low в целом он хороший, напоминает голос ведущей новостей, но с ударениями беда. А uk_UA-ukrainian_tts-medium почему-то не заработал. Вместо озвучки выдавал какие-то завывания.
Модели можно установить, перейдя на страницу со списком всех версий приложения и языковых пакетов(Алярм, страница ещё длиннее, чем эта статья). Стоит заметить, что одновременно может быть установлен только один языковой пакет.
Если же хотите только послушать, как звучат нейро-голоса, их можно опробовать на специальной странице.
Какой вывод из этого сравнения можно сделать? Если б мне понадобилась «говорилка», использовал бы RHVoise.
Я бы мог и дальше рассказывать про то, как технологии помогают людям с ограниченными возможностями, но, к сожалению, тогда уйду от темы в заголовке, да и статья уже прилично растянулась. Хотя дайте знать, если хотите про это прочесть. Очень много интересной инфы нашёл, так что, если что, с удовольствием про это сделаю отдельный выпуск (хотя, может, даже отдельный цикл статей посвящу... Ну, посмотрим).
Вы могли заметить, что прошло уже больше половины статьи, но никаких «ужасов», обещанных в названии, пока не было. Это связано с методами, которые обсудили. Ни параметрический, ни формантный синтез не звучат по-человечески, а значит, их нельзя использовать для мошеннических схем (разве что переозвучить видео со Стивеном Хокингом, используя «Perfect Paul»). Но следующий тип, который рассмотрим, подходит для имитации человеческой речи. Ведь нет ничего более похожего на человеческий голос, чем он сам.
314 кабинет
Тип синтеза, о котором пойдёт речь, это комкатен... компакет... кон-ка-те-на-тивный, о! Лучше буду использовать альтернативное обозначение, компиляционный (или компилятивный) синтез. На самом деле метод его работы гораздо проще, чем название. При таком подходе голос не с нуля синтезируется, а берётся заранее записанные образцы речи, из которых складывается предложения. Голосовые отрезки могут содержать как один слог, так и целые слова или даже предложения.
Например, в прошлой части я упоминал, что для одного датасета использовали записи телефонных пранкеров про 314 кабинет. Примечательно, что эта разновидность издевательств называется «технопранками». В них жертва общается не с самим пранкером, а с отрывками фраз другой жертвы.
Например, в случае ниже пранкеры позвонили в военкомат и использовали запись какого-то сторожа.

Вот как это работает. Вначале пранкер звонит людям, ставит вместо своего голоса отрывки фраз других людей и записывает ответы жертв. Например, запись с фразами про 314 кабинет была сделана при общении сотрудника военкомата с отрывками речи т. н. «бабки АТС», взятыми из знаменитого телефонного розыгрыша начала нулевых. Далее пранкер режет разговор на фразы и составные части, подготавливая таким образом базу данных. Используя получившийся «датасет», он звонит другим людям и воспроизводит получившиеся отрывки речи предыдущей жертвы, более-менее подходящей к текущей ситуации.
Лично я не понимаю, что забавного в издевательстве над рандомными людьми. Самая адекватная реакция была у одного сотрудника военкомата, которому уже не в первый раз звонили. Он просто клал трубку, не давая пранкеру возможности обогатить свою базу новыми фразами. Впрочем, тот и на этом сделал «контент».

Пробив номера с регистрацией и СМС
Занимательный факт: пока это всё гуглил, натыкался на ботов, которые за маленькую плату могут позвонить на определённый номер и включить один из сценариев на выбор. Хотя из примеров, которые видел, там скорее нейронный синтез, а не склейка фраз (но не исключаю, что и подобные боты есть).
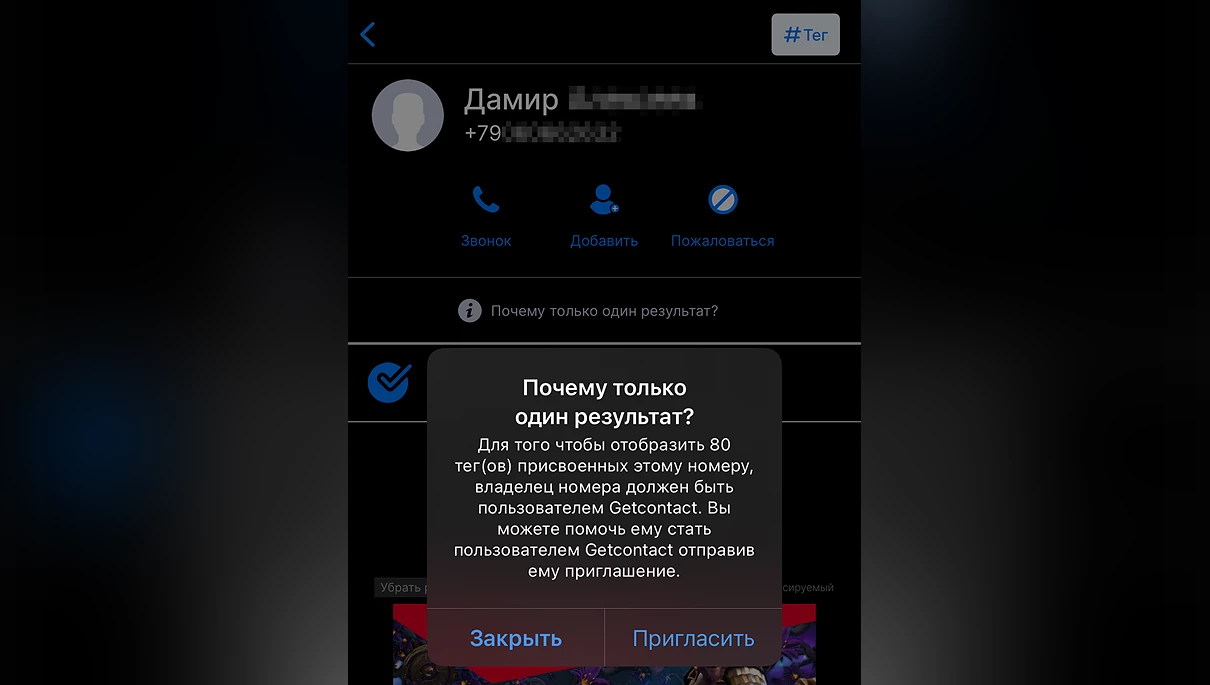
Поэтому не отвечайте на провокации телефонных хулиганов. Хотя, наверное, в последнее время это и неактуально. Давно уже есть программы вроде Getcontact, которые предотвращают спам, показывают, как номер подписан у других пользователей, и, естественно, пополняют базу данными из вашей телефонной книги. По ссылке инструкция, как запретить Getcontact это делать (она была актуальна в 2023 году, как сейчас с этим — не знаю). Ваши данные в подобных программах могут быть, даже если лично вы ими не пользовались, т. к. его могли использовать люди, у которых есть ваш номер.
Например, одни подписали вас как «Саша Слесарь», и теперь всем ясно, кем вы работаете. «Папа», «Муж», «Зять» рассказывают о вашем семейном положении, а «Пушкина 30» — ваш адрес. И вот таким образом, только на основе этих тегов, формируется база, которая доступна всем желающим. По вышеприведённой ссылке есть инструкция по удалению информации о вашем номере из их баз.
Промежуточные итоги
Да, мне потребовался заголовок, чтоб разделить темы пробива номера и синтеза речи.
Т. е. компилятивный синтез речи — это склейка записей голоса одного человека (соединение голосов разных людей — это уже RYTP). Например, он применяется для озвучки остановок в транспорте или в синтезаторах вокала. Что? Что такое синтезатор вокала? Как хорошо, что вы спросили, как раз хотел о них поговорить.
Ultimate Sempai
Ура! Вот и добрались до моей самой любимой темы. Стиль поменялся, потому что вряд ли кто-то до сюда дойдёт, так что можно, не опасаясь, нести всякую чушь! Для начала хочу поделиться одним роликом, чтоб, если вдруг кто-то читает этот бред текст, мог настроиться на дальнейшую деграда шизо часть статьи.

Эта песня к вокалоидам имеет такое же отношение, что и Stronger Than You к Undertale.
Наверняка вы знали о существовании вокалоидов и, возможно, даже слышали некоторые песни, спетые несуществующими анимешными девочками. Нет? Хм, тогда вкратце объясню.
Vocaloid (vocal + android) — это программа от компании Yamaha, через которую любой* желающий может создать синтетический вокал на основе текста. Для этого используются войсбанки (voiсebank) — набор данных, содержащий в себе как вокальное звучание всех вариаций фонем и слогов, записанные певцом или сэйю, так и словарь для правильного преобразования букв в отдельные фонемы. На текущий момент доступна шестая версия программы с возможностью бесплатного месячного пробного периода (для её активации не требуют вводить данные карты, как это обычно бывает в подобных «бесплатных» периодах).
Также в просторечье под словом «вокалоид» могут подразумевать не только саму программу, но и синтезированные голоса для неё. Хотя корректнее называть их войсбанком (VB) или виртуальными певцами.
К слову, VB могут записываться сторонними фирмами. Так, например, известный виртуальный исполнитель Хатсуне Мику (чей голос основан на записях сэйю Саки Фудзиты) создана компанией Crypton Future Media (которая также родила на свет не менее популярных Кагаминэ Рин и Лен).
Голос Мику можно послушать в этой песне:

Как можете слышать, пение звучит очень красиво. Мику была представлена ещё в 2007 году, и с годами её голос становился только лучше. Для сравнения, так она пела 15 лет назад, а так — в прошлом году. Если хочется узнать, о чём песня, рекомендую этот кавер.

Виртуальные певцы ездят в турне, устраивают концерты и собирают многотысячные залы. Так, во время мирового турне Miku Expo 2024–2025, Мику посетила с десяток стран, расположенных на разных континентах: от стран Европы и Северной Америки до Австралии. Одно из выступлений проходило в Сиднее, и по утверждению 9Honey, на нём присутствовало до 9000 зрителей.
Вот как выглядел подобный концерт прошедший в Мехико.

Для показа самой виртуальной звезды использовался LED-экран, что разочаровало некоторых фанатов, ведь раньше применялись красивые голографические проекции, как показано ниже:

Только посмотрите, как создаётся иллюзия взаимодействия со сценой, начиная с 7:14. А с появлением бездушного телевизора посреди сцены официальный тур почти не отличим от фанатских концертов. Разве что аудитория побольше и живой инструментал есть. Для сравнения, вот так выглядел полностью бесплатный концерт, устроенный в 2025 году фанатами для фанатов.

Та даже концерт, организованный одним человеком, выглядит довольно круто. Тут автор использовал специальную конструкцию с натянутой плёнкой обратной проекции. (По этой ссылке показано, как он её собирает).

С юридической стороны у таких концертов всё прозрачно. Разрешения у создателей Hatsune Miku, т. е. компании Crypton, нужно спрашивать только если хотите использовать персонажа в коммерческих целях (на платных концертах или в рекламе).
Тем не менее персонажей можно использовать в рамках партнёрской программы YouTube, без предварительного согласования с компанией. Например, так Pinocchio-P в своих клипах использует чиби-версию Мику. И вот ссылка на кавер (а вы думали, зачем я столько воды развёл? Всё, чтоб поделиться любимыми треками).

Но такие правила касаются только самого персонажа. На вокал никаких ограничений нет. Если у вас есть лицензия на голосовой банк, можете свободно её применять в коммерческих целях, где только пожелаете. Например, для озвучки собственных песен с оригинальным персонажем, как в этом случае.

Сделаю небольшое отступление (моя статья, что вы мне сделаете... А, ну да, читать прекратите. Не прекращайте, пж), чтобы отдельно и кавер показать. Невероятно шикарный перевод и вокал. Жаль, что у автора так мало подписчиков.

UPD. Перед самой публикацией, на официальном канале Хатсуне Мику появился ролик с проходившего недавно JAPAN LIVE TOUR 2025 ~BLOOMING~. В нём виртуальная певица совместно с Касанэ Тэто (уталоид, изначально созданный как шутка на «2ch») исполняет «MESMERIZER» (ссылка на кавер). Для их отображения использовались проекторы, поэтому они выглядят очень живо и объёмно.

Так, о чём тема статьи... А, точно! Синтез речи! Опять куда-то не туда ушёл.
Как уже говорил, в вокалоиде синтез речи осуществляется путём склейки фрагментов записей вокала. В войсбанк входят как сами фонемы, так и звучание переходов между ними (чтобы можно было, как в пазле, соединять одни фрагменты с другими). В туториале, приведённом ниже, на отметке 7:58 можно услышать пример записываемых данных.

Более подробнее про типы голосовых банок можно прочесть в этом разборе от UTAU-сообщества. Что такое UTAU? Это название стороннего синтезатора, работающего по тому же принципу, что и Vocaloid, только распространяемого условно бесплатно (также есть полностью бесплатный проект OpenUtau). Если что, за сам «Vocaloid 6» и 22 войсбанка к нему просят $225 (а дополнительные голоса продают в основном за $90 — $100). Может, для известных композиторов или групп это ещё норм, но для энтузиастов и любителей цена довольно кусачая.
Тем не менее, такая цена может быть связана с их качеством. Уталоиды же (VB, сделанные для UTAU), хоть и в большинстве своём бесплатные, звучат гораздо хуже. Кстати, голосовые пакеты могут быть и русскоязычные. Например, вот компиляция звучаний 29-ти таких VB.

Как можете слышать, некоторые поют вполне неплохо (например, M1NTO, CD_Rusya или Genki Tatsu, хотя последнему накинул очки за песню, которую исполнял), в то время как у других было проблематично разобрать слова без сверки с текстом. Но тем не менее, порой и из уталоидов можно выжать прекрасное звучание. Например, в этом кавере на «Прекрасное далёко» автор мастерски поработал со звучанием.

Кстати, на видео показан интерфейс Utau. Он не сильно отличается от вокалоида, поэтому вкратце опишу принцип работы. Та бегущая вермишель посередине кадра — дорожка вокала. Каждый блок — отдельный сэмпл звука, который можно склеить с другими, поменять тональность, добавить вибрато и изменять как душе угодно. Много о чём ещё хотел бы поговорить, но, к сожалению, пора бы закругляться, а я ещё не упомянул довольно интересную фишку вокалоида.
В пробном бесплатном периоде «Vocaloid 6» доступны только модели Vocaloid:AI, которые работают по четвёртому и последнему типу, о котором хотел сегодня рассказать, нейронному. Самый лёгкий для понимания тип.
- Нейронке скармливается датасет (в данном случае записи пения певца, а не отдельные фонемы. Записи делаются легально).
- Система анализирует стиль, особенности пения и прочие факторы.
- На выходе получается очень живой вокал, который можно спутать с реальным.
Представили эту технологию довольно оригинально, «воскресив» голос умершей в 1989 году певицы Хибари Мисора.

Голос звучит очень чисто. Прям мурашки по коже (во всех возможных смыслах).
Более подробно про последний расскажу в следующей статье. А пока в качестве затравки, оставлю ссылку на песню, сгенерированную в SunoAI.
Итоги
В статье разобрал 4 метода синтеза речи с наглядными примерами. Подытожу:
Фонемный — когда звук, проходя через фильтры, превращается в понятные буквы.
Пример: голос Стивена Хокинга, «Perfect Paul».
Параметрический — предсказывает благозвучную последовательность звуков, опираясь на сам текст, знаки препинания и правила построения слов.
Пример: TTS, в частности RHVoice.
Компилятивный — склейка из отрезков речи (слогов и слов), находящихся в базе.
Пример: Вокалоиды.
Нейронный — ИИ обучается на большой базе данных и старается ей подражать.
Пример: Хибари Мисора (если вы просто прокрутили всю статью и не знаете, кто это, гляньте верхнее видео).
Послесловие
Наконец-то дописал эту статью. Делитесь в комментариями о том, что думаете насчёт тем, затронутых в ней, длины полотна или темах, которые хотите, чтоб о(б)судил в следующей части. Особенно интересуют ваши любимые песни вокалоидов.
Также хочу заверить, что данная статья целиком и полностью сделана при помощи нейронной сети. Если точнее, то в процессе могло участвовать до 86 миллиардов нейронов (точное количество, которое использовалось для написания статьи, подсчитать не представляется возможным).
Ну а на этом у меня всё. До следующей части, если меня в дурку не упекут.
Пост создан пользователем
Каждый может создавать посты на VGTimes, это очень просто - попробуйте!-
![]() Исследование: ChatGPT формирует «когнитивный долг», снижая активность мозга
Исследование: ChatGPT формирует «когнитивный долг», снижая активность мозга -
![]() ТОП-40 лучших игр про выживание на PC
ТОП-40 лучших игр про выживание на PC -
![]() ТОП-30 самых сложных игр — вам будет больно
ТОП-30 самых сложных игр — вам будет больно -
![]() ТОП-70 игр в открытом мире. Вам точно будет, чем заняться
ТОП-70 игр в открытом мире. Вам точно будет, чем заняться -
![]() ТОП-45 лучших порно игр для взрослых: развратные вечеринки, БДСМ и секс в аду (18+)
ТОП-45 лучших порно игр для взрослых: развратные вечеринки, БДСМ и секс в аду (18+) -
![]() ТОП-205: лучшие кооперативные игры в 2025 году
ТОП-205: лучшие кооперативные игры в 2025 году -
![]() ТОП-20: лучшие кооперативные хорроры (2021-2025)
ТОП-20: лучшие кооперативные хорроры (2021-2025) -
![]() ТОП-45 лучших порно игр для Android и iOS: волшебные «палочки», атака тентаклей и совращение милф
ТОП-45 лучших порно игр для Android и iOS: волшебные «палочки», атака тентаклей и совращение милф -
![]() ТОП-30: лучшие кооперативные игры для PS4 и PS5 — во что поиграть с друзьями на одной консоли
ТОП-30: лучшие кооперативные игры для PS4 и PS5 — во что поиграть с друзьями на одной консоли -
![]() Лучшие мобильные игры для двоих на iOS и Android (на 2025 год)
Лучшие мобильные игры для двоих на iOS и Android (на 2025 год)









