Что такое нейросети и кому они нужны? Как установить и настроить Stable Diffusion, как обучить её новым стилям и понятиям. Интервью VGTimes с основателями сервиса NeuroFox
 Никита Шилов
Никита Шилов
Нейросети с каждым днем становятся всё умнее, а созданные ими изображения всё труднее отличить от работ художников. Мы решили раз и навсегда разобраться с этим вопросом и рассказать, что это за чудо, как оно работает, как скачать и настроить Stable Diffusion («картиночную» нейросеть, доступную всем) и почему «картиночные» нейросети — лишь начало. В этом нам помогут представители российского сервиса нейросетевых технологий NeuroFox.pro, который даёт доступ к онлайн-версии Stable Diffusion с дополнительными модулями стилей.
Почему именно Stable Diffusion?
На данный момент это самая доступная нейросеть, которую может скачать и установить себе на компьютер любой желающий. А если у вас нет достаточно мощной видеокарты, можно воспользоваться онлайн-сервисом, например, тем же NeuroFox.pro или вовсе сгенерировать что-нибудь в «облаке», хотя в последнем случае придётся поиграться с настройками.
К тому же у Stable Diffusion (далее SD) есть множество различных модулей, которые способны «рисовать» в самых разных стилях, и несколько версий интерфейсов, содержащих различные настройки, в том числе для видеокарт с небольшим количеством видеопамяти.

Так что вы вполне можете посидеть пару часов в онлайне, разбираясь в принципах генерации, а после скачать и установить себе на компьютер локальную версию SD, в которой можно настроить всё так, как вам удобно: загрузить понравившиеся модели, улучшить полученную картинку и даже обучить программу, к примеру, генерировать изображение с вашим участием или любимыми персонажами и предметами. С DALL-E 2 или MidiJorney такой фокус, конечно, не пройдёт.

Мы расскажем и о том, как именно работают нейросети в целом и Stable Diffusion в частности, а после разберем, как подготовить всё необходимое, и научимся создавать первые запросы.
Создавали картинки с помощью нейросетей?
Что такое нейросеть?
Понимание этого вопроса, конечно, не сделает из вас программиста, но если вы будете знать, как именно работают нейросети, задавать исходные параметры и генерировать нужные изображения станет значительно проще. Но вы в любой момент можете пролистать ниже, начав процесс скачивания и установки SD, или перейти к вопросам непосредственной генерации изображений.
Итак, что такое нейросеть? Это упрощенная модель мозга. У нас в голове есть два элемента, благодаря которым мы думаем — нейроны и синапсы. Они образуют невероятно сложную сеть, одних нейронов в нашей голове больше восьмидесяти миллиардов.
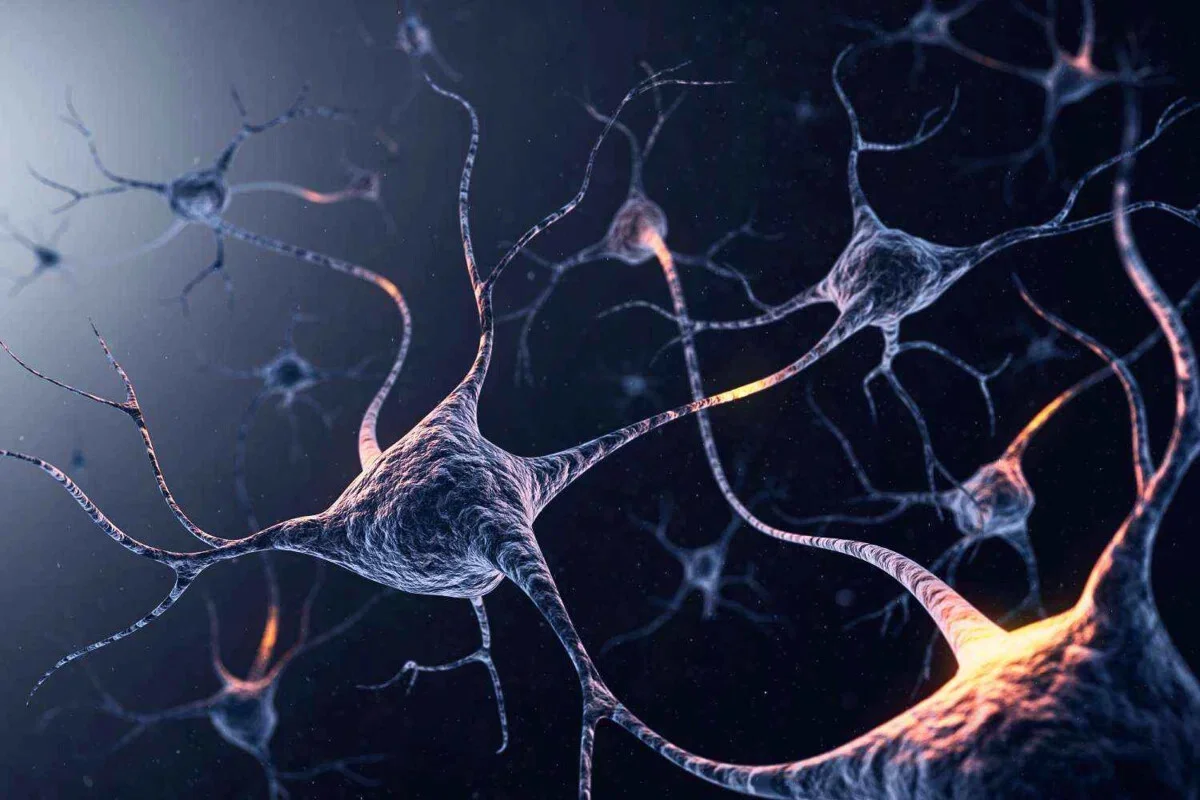
Когда мы думаем, нейрон получает сигнал (информацию), обрабатывает его и отправляет ответ дальше по связи-синапсу. И, в зависимости от толщины синапсов, которые связывают нейроны, информация доходит или не доходит до определенного «места» в сознании по другим нейронам.
Когда мы запоминаем информацию или получаем навык — мы усиливаем связь между соответствующими нейронами, где хранится нужное нам знание. Именно благодаря такому механизму мы и способы обучаться, помнить, чувствовать (моральный компас — тоже набор нейронов и их связей) и принимать решения.
Компьютерная нейросеть имеет схожее строение. Только вместо думающего нейрона — простой алгоритм, а вместо синапса — «вес» решения, его важность в общей картине. Закрепим на небольшом примере.
Нам надо принять решение, пойдём ли мы гулять или нет. Мы любим гулять «по солнышку» или в выходные (1). Но не любим бродить под дождём или заняты работой (0). Если в третьем нейроне мы получим 1, то отправимся на прогулку. Единица в данном случае — положительное решение, а 0 — отрицательное.
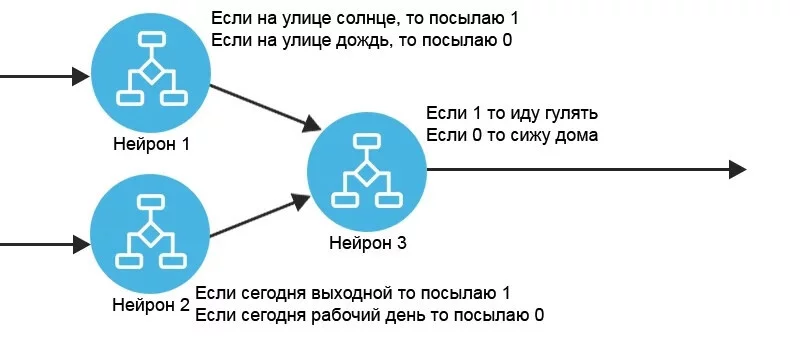
А теперь принимаем решение. Солнце светит? (1) Идем гулять (1). Идет дождь и сегодня рабочий день? (0) — сидим дома (0). А вот если наступил выходной (1), то даже если идёт дождь, мы идём гулять (1), ведь свободного времени много. Если хотя бы один из нейронов 1 и 2 имеет вес 1, то нейрон 3 тоже принимает положительное (1) решение.
Нейросети работают по похожему принципу, только, как и в мозге, вес их связей не ограничен двумя значениями — 0 или 1, в «нейронах» сидят куда более крутые алгоритмы, а от количества искусственных нейронов зависит сила и возможности нейросети. Но принцип тот же.
Например, у нас есть нейросеть-определитель птичек. Мы кидаем ей картинку тукана, она преобразует изображение в набор чисел, а после пропускает через себя. Нейросеть увидела клюв (1), перья (1) и крылья (1), но не увидела пышный хвост (0) и, к примеру, когти (0). В итоге она, пусть и сомневаясь, выдаст вердикт, что на картинке — птица (1).
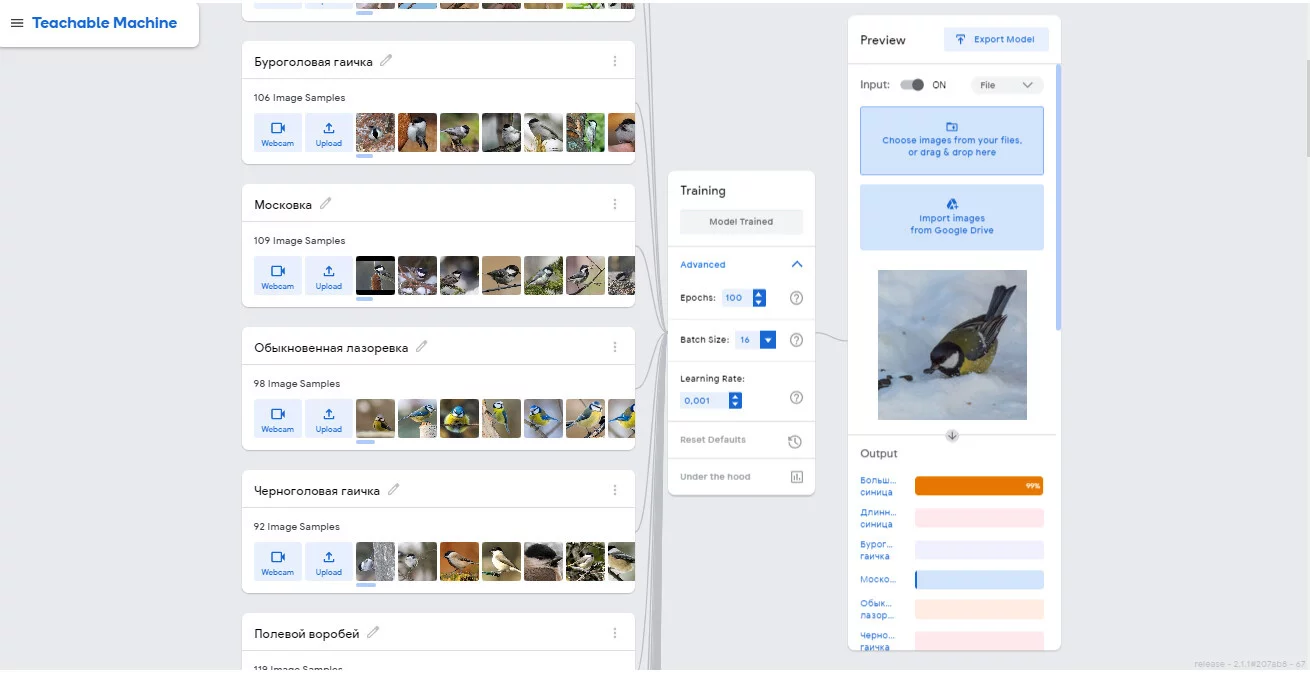
Мы упрощаем устройство нейросетей, поскольку иначе пришлось бы расписывать все хитрости почти бесконечно. И даже больше — когда мы начнём говорить об устройстве Stable Diffusion, на нас ополчатся все программисты мира, ведь «картиночные нейросети» — не нейросети вовсе, а сложные программы, состоящие из нескольких независимых модулей, лишь часть из которых — нейросети.
Как работает Stable Diffusion и её аналоги?
Как мы уже упомянули, Stable Diffusion и другие проекты, генерирующие изображения «из ничего», — это не просто нейросети, а сложно устроенные программы. Чтобы понять, как они работают, надо сначала разобраться, как их научили работать. И для этого придётся всё сильно упростить, но, надеемся, что нас за это простят те самые программисты.
Итак, за обучение отвечает отдельный модуль — предсказатель шума. Представим, что у нас есть изображение пирамиды. Вы видите его ниже. Мы берем и добавляем туда немного шума.

В итоге имеем три картинки — оригинальное изображение, «срез шума 1» («noise slice 1») и полученную «шумную картинку». Теперь мы повторяем операцию, вновь накладывая «срез шума» под номером 2 и получаем… мешанину из шумов!
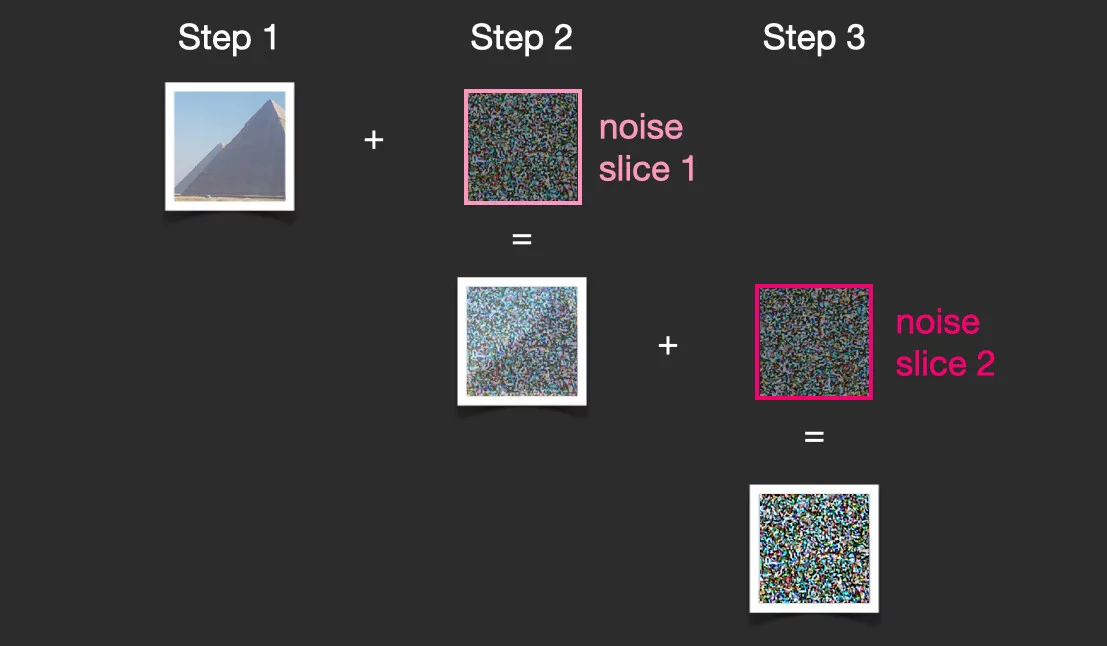
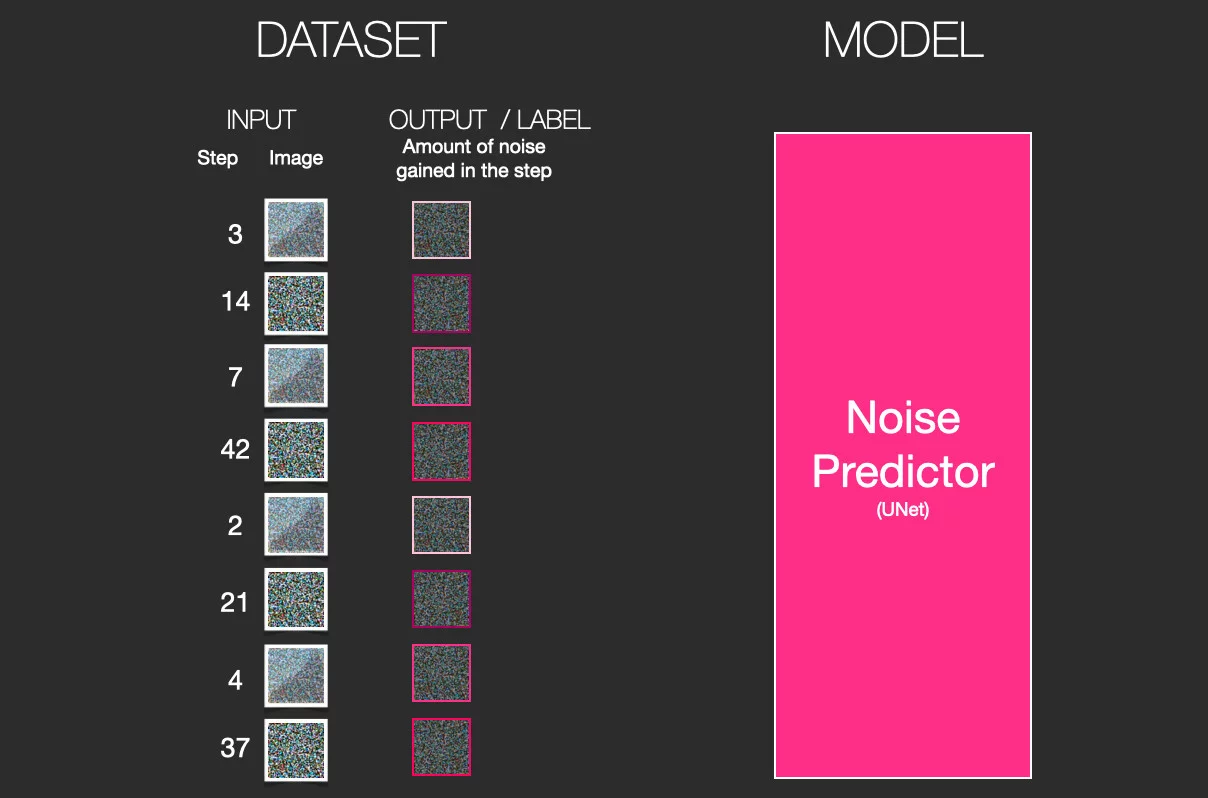
Теперь настало время обучать нейросеть! У нас есть номер шага и два изображения. Задача нейросети: понять, какое количество шума мы добавили на картину.

Конечно, за два шага сделав из пирамиды сплошной шум, мы лишь скинем нашу только родившуюся модель со скалы, прямо как в Спарте. В реальности нейросеть обучают, добавляя по капельке шума и разбивая этот процесс на 50 и более срезов.
Обученная таким образом модель будет рисовать изображение пирамиды из шума, который ей дают, по кусочку «откатывая» шум к самому первому изображению пирамиды. При этом с каждым «шагом» получаемое изображение будет чуточку ближе к тому, с которого обучалось.
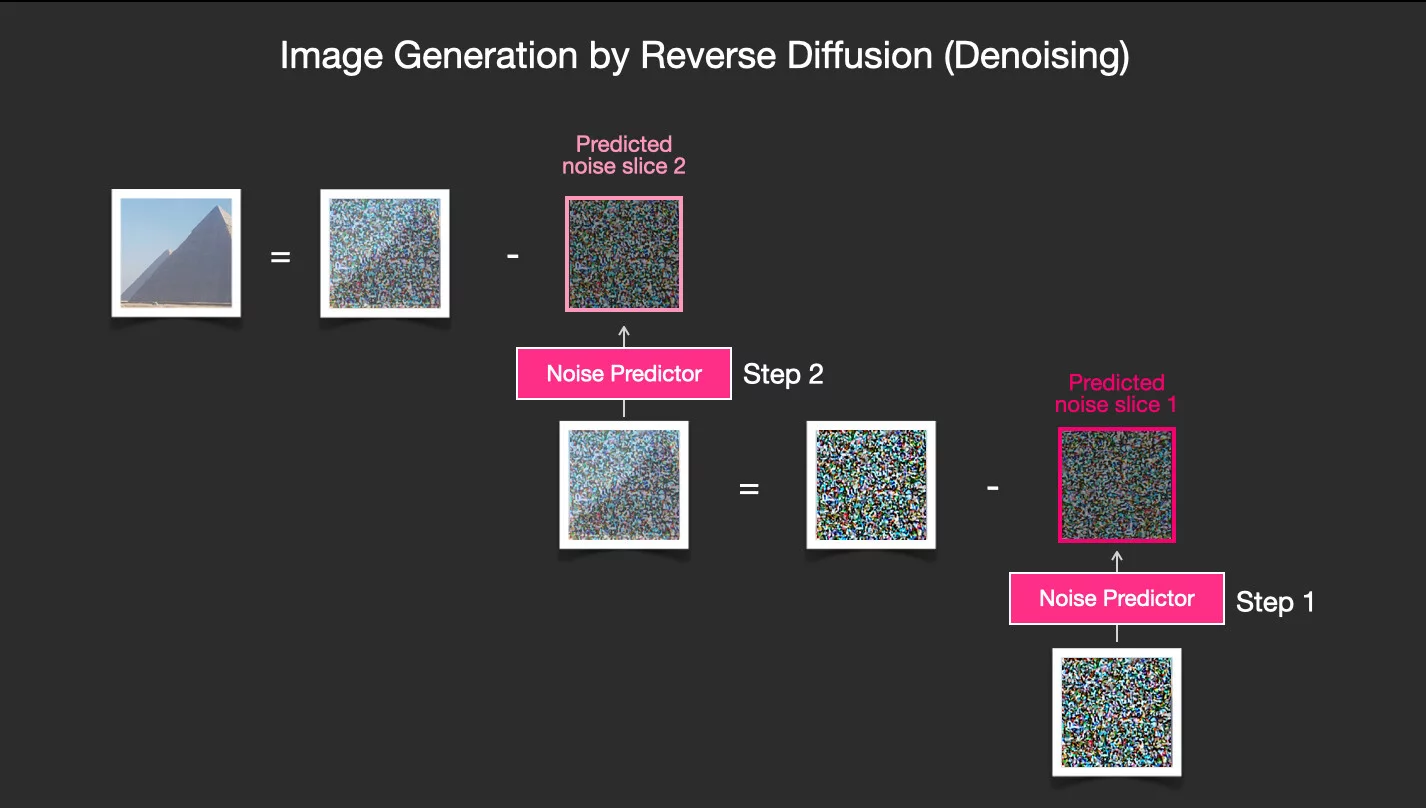
Но Stable Diffusion, конечно, таким образом не сделать, ведь пирамида в итоге будет одна! И неко-вайфу в костюме космодесантника из этой пирамиды никак не получить.
Поэтому в дело вступает второй модуль — текстовый. Для обучения нейросети скармливают не только фотографии, но и их описание с помощью отдельных тегов. А этот модуль преобразует теги в ряд чисел — вектор-табличку, которая «крепится» к определенному срезу шума, и потом, когда программа видит, что вы хотите сгенерировать котика в шлеме драконорожденного, она будет искать именно такие срезы шумов, которые бы подошли в данной ситуации.
Это и есть главный секрет программ, генерирующих изображения. Они буквально работают наоборот. Не создают изображение, а в буквальном смысле уйму раз стучат по сочетанию клавиш «Ctrl+Z», в качестве «направления движения» используя те текстовые теги и описания, на которых их учили.

Отличие Stable Diffusion от многих других генераторов в том, что никаких «шумных картинок» внутри программы нет — это слишком долго и затратно по ресурсам. Вместо того, чтобы каждый раз генерировать картинку и потом что-то в ней менять, SD манипулирует математическими данными, работая внутри «скрытого пространства», лишь в последний момент преобразуя числовую модель в понятное нам, людям, изображение. Это куда выгоднее и быстрее, иногда — в десятки раз.
В итоге мы имеем три главных модуля:
- Кодировщик текста, превращающий запрос в набор данных;
- «Скрытое пространство», которое шаг за шагом подбирает подходящие по описанию «срезы шума»;
- Генератор изображения, который из финального массива данных создает приятную глазу картинку.
Всё это — грубое упрощение, но зато достаточно понятное человеку со стороны. Понимание принципа работы Stable Diffusion позволит лучше строить текстовые запросы, управляться с «весами» и другими параметрами программы.
Как установить Stable Diffusion на PC?
Для скачивания локальной версии Stable Diffusion понадобится Python 3.10.6, Git и сама Stable Diffusion — придётся зарегистрироваться на сайте huggingface.co. С видеокартами AMD SD работает только через «костыли» из-за проблем с драйверами и архитектурой, это нужно иметь ввиду.
На выходе мы получим готовую к работе программу с удобным веб-интерфейсом, для использования которой не требуется консоль. Теперь поэтапно:
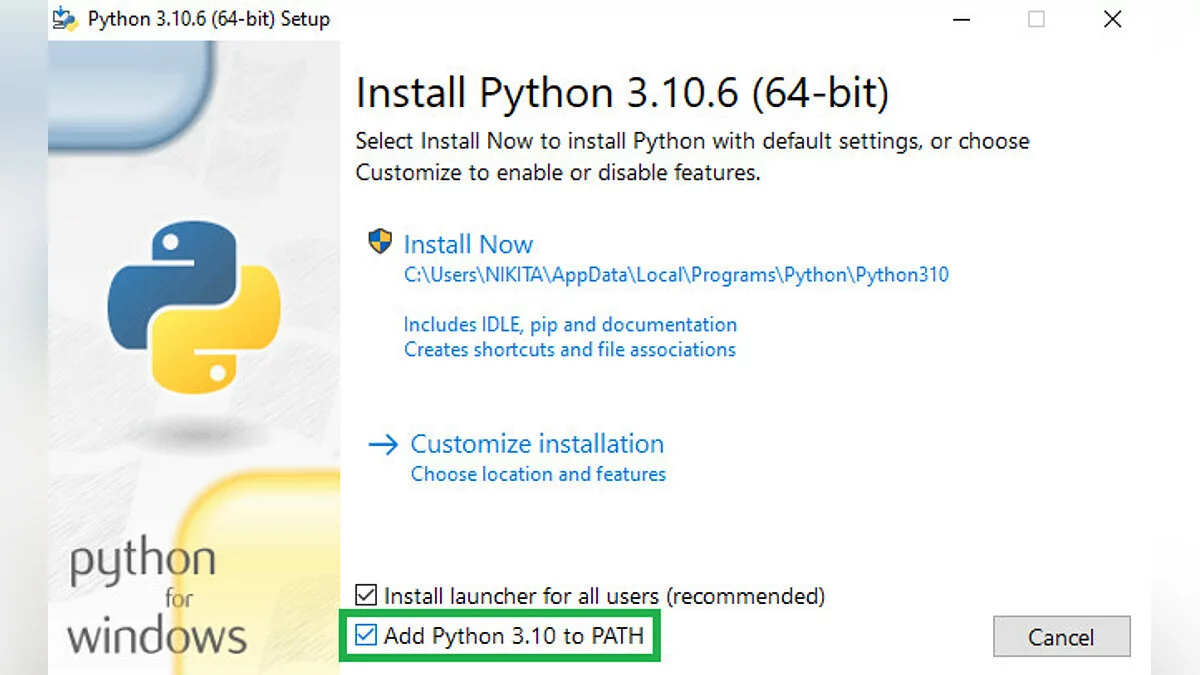
- Скачиваем Python отсюда и устанавливаем, не забыв поставить галочку напротив пункта «Add Python 3.10 to PATH». Это необходимо для стабильной работы SD.
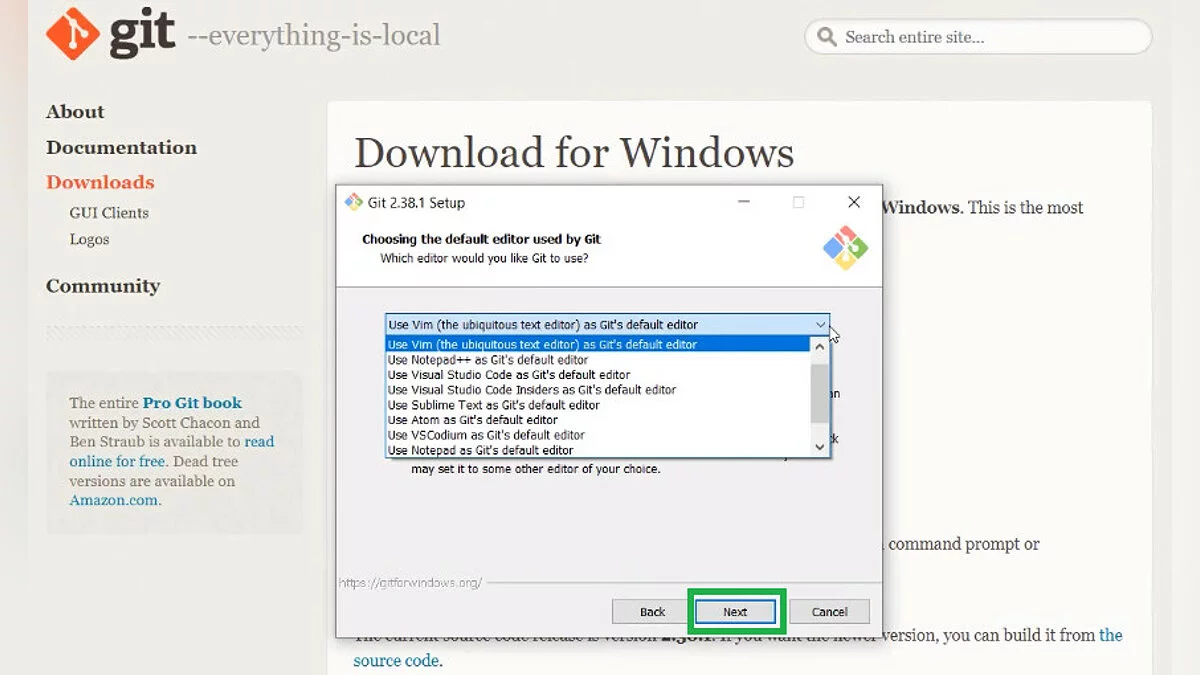
- Переходим по этой ссылке, скачиваем и устанавливаем Git, прокликав «Next» до самого процесса установки. Никаких дополнительных действий на этом шаге не требуется.
- Создаём папку, в которой будем хранить Stable Diffusion. Нужно учитывать, что там же будут храниться и модели нейросети, многие из которых весят по несколько гигабайт.
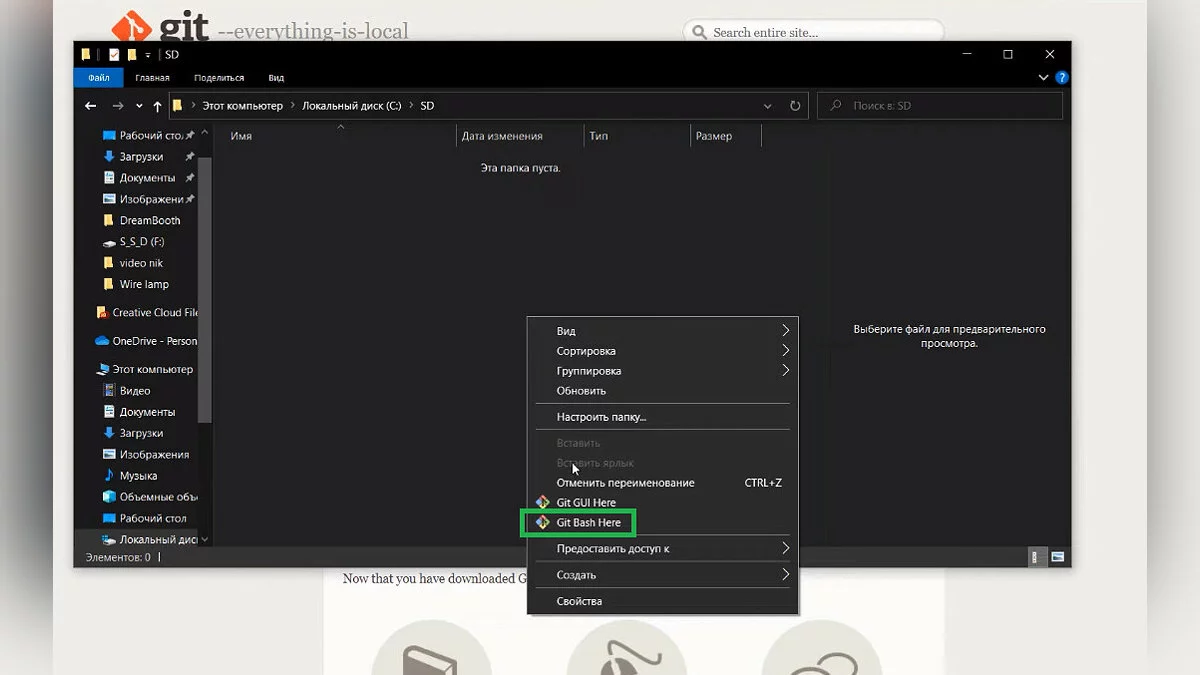
- Открыв папку, правой кнопкой мыши кликаем на свободном месте и нажимаем на появившийся пункт «Git Bash Here».
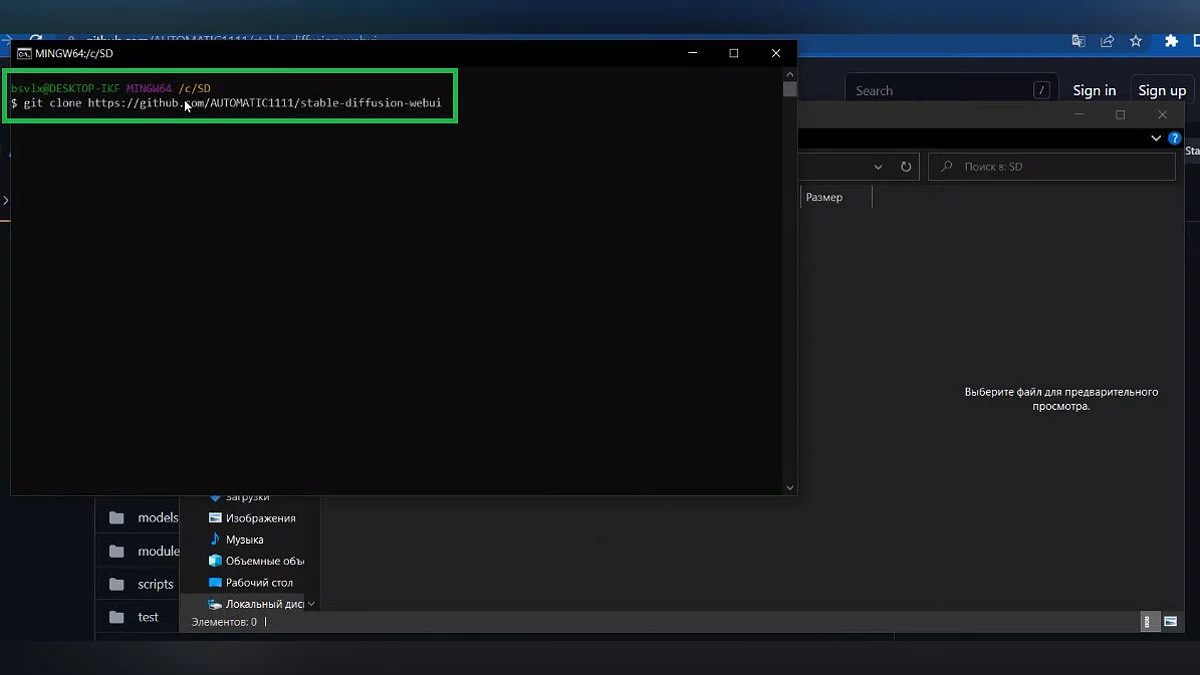
- В открывшейся командной строке вводим команду «git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui», после чего нажимаем «Enter» и ожидаем завершения процесса. Благодаря этому модулю мы получим возможность работать с Stable Diffusion в браузере. Закрываем командную строку.
- В появившейся папке «stable-diffusion-webui» переходим по следующему пути: «stable-diffusion-webui\models\Stable-diffusion». Сюда мы будем копировать скачанные модели и основное ядро SD.
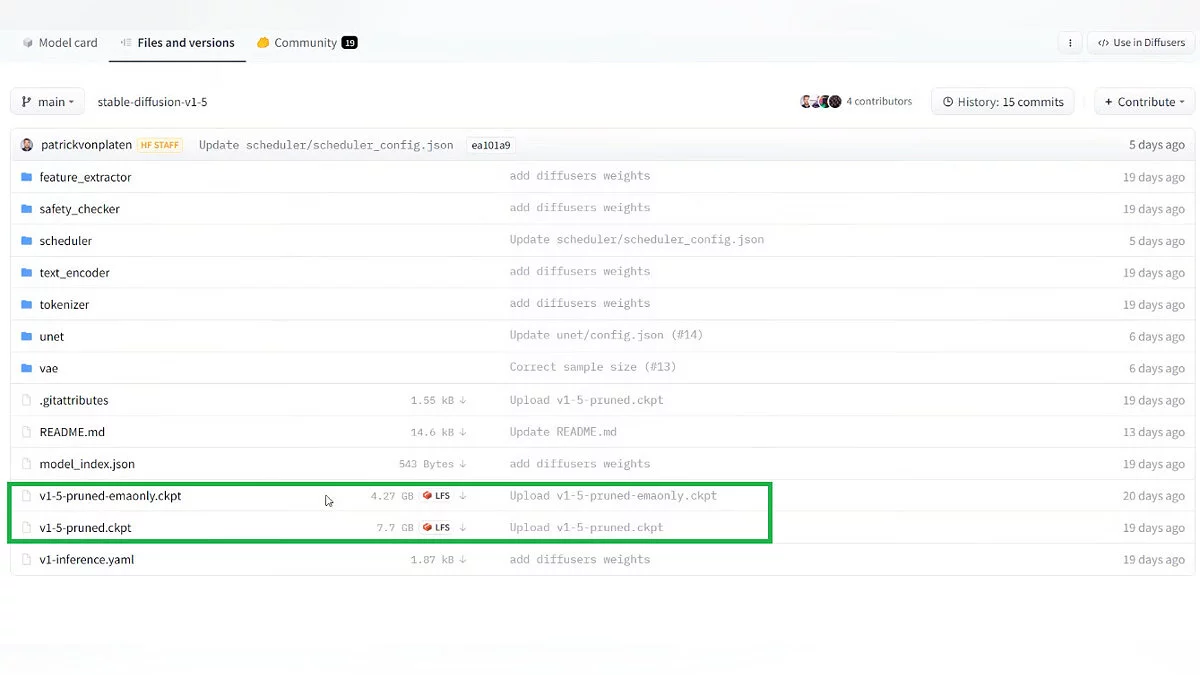
- Переходим на страницу Stable Diffusion, авторизуемся/регистрируемся на сайте, идём на вкладку «Files and versions», откуда скачиваем файлы «v1-5-pruned-emaonly.ckpt» и «v1-5-pruned.ckpt». Первый — основное ядро SD 1.5, которое уже способно на многое. Второй — доработанное ядро, которое лучше поддается обучению. После скачивания копируем эти файлы в папку из пункта 6.
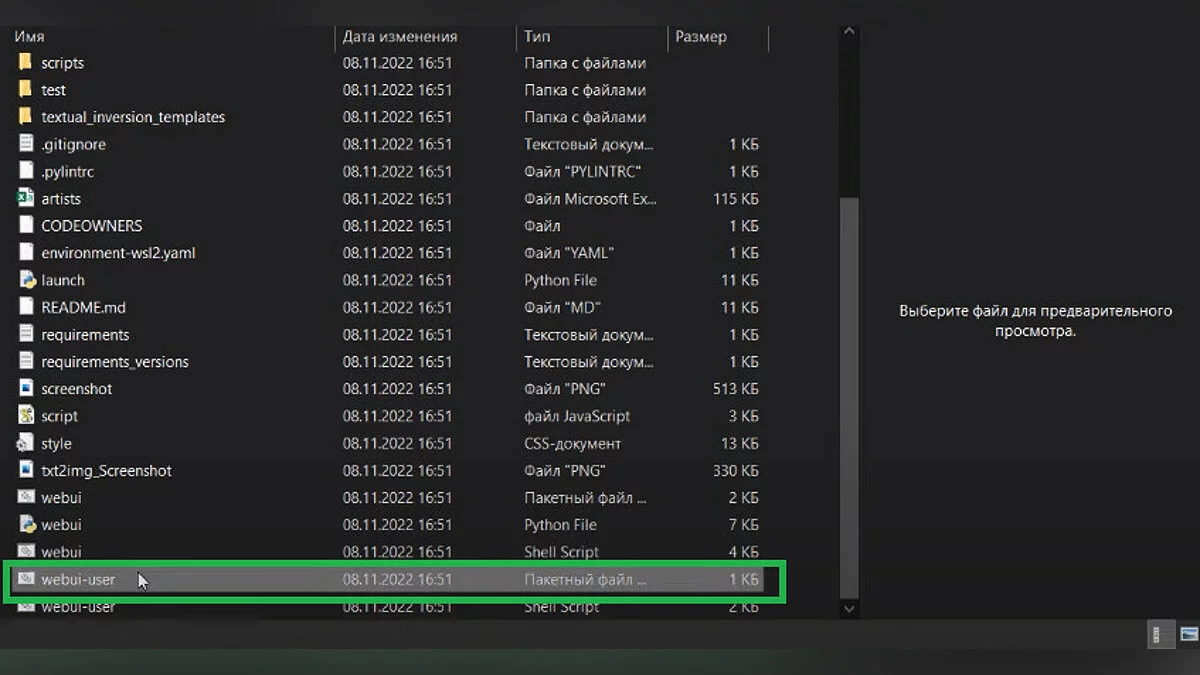
- Запускаем файл «webui-user.bat». Если вы видите фразу «Installing torch and torchvision» или «Installing gfpgan», всё в порядке — программа скачивает всё необходимое. Можете убедиться в этом, открыв диспетчер задач и увидев, как Python потребляет ваш интернет-трафик. Если что-то пошло не так — мы разобрали возможные ошибки ниже.
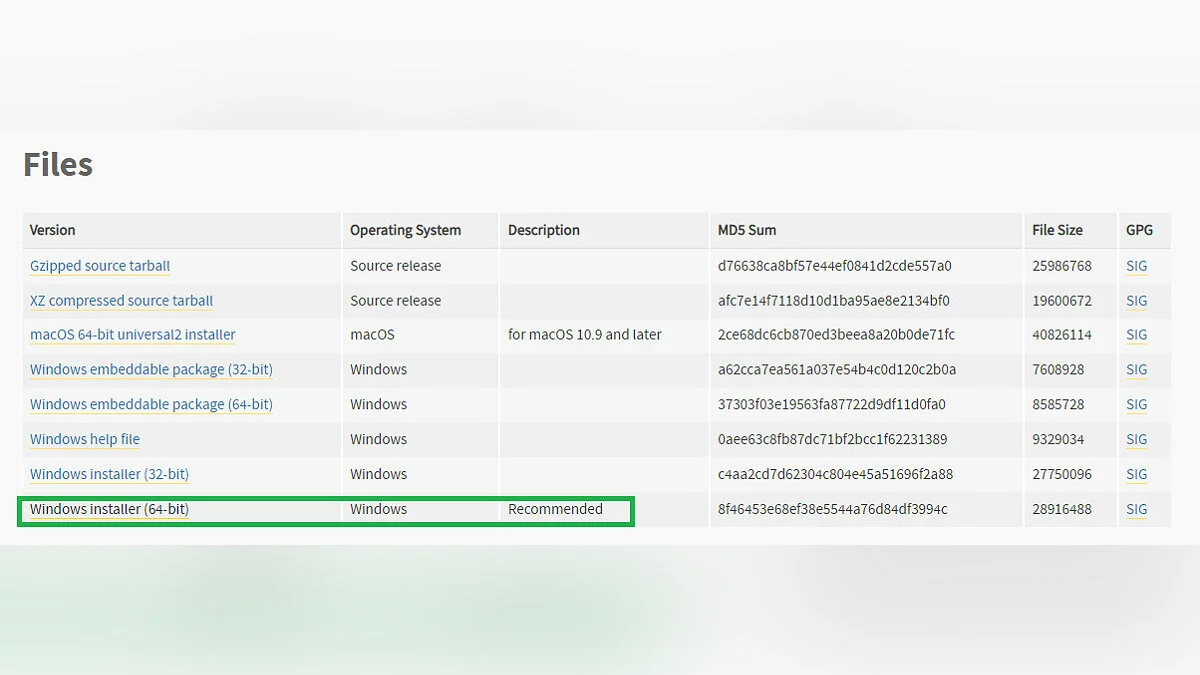
Когда процесс будет завершен, в командной строке появится сообщение «Running on local URl:» с адресом. Его необходимо скопировать и вставить в браузер. Так вы откроете Stable Diffusion. Добро пожаловать в мир нейросетевых технологий!
Возможные ошибки при запуске:
- «Couldn't launch Python». Скорее всего, вы забыли установить галочку напротив «Add Python 3.10 to PATH» при установке Python. Необходимо переустановить программу, либо вручную указать путь до «Python.exe».
- Если у вас видеокарта с 4 Гб видеопамяти и меньше или при использовании SD появляются ошибки о недостатке памяти, необходимо дополнительно прописать свойства в «webui-user.bat». Для этого откройте файл в блокноте и в строке «set COMMANDLINE_ARGS=» после пробела допишите «--medvram». Другие варианты аргументов можно найти на этой странице в разделе «Low VRAM Video-cards». Возможна работа Stable Diffusion даже при 2 Гб памяти, но скорость генерации будет низкой.
- «CUDA error: no kernel image is available for execution on the device». Проблема совместимости файлов xformers с вашей видеокартой. Если вы используете Python 3.10, имеете карту Pascal (серия 1000 и выше) и работаете в Windows, добавьте «--reinstall-xformers --xformers» в «COMMANDLINE_ARGS» для обновления до рабочей версии. Затем удалите команду после обновления.
- «NameError: name 'xformers' is not defined». Не та версия Python. Вернитесь к инструкции по установке и проверьте, корректная ли версия скачана. Необходим Python 3.10.6
Как получить более красивые результаты в Stable Diffusion. Разбираемся в настройках генерации
Для начала, попробуем создать самый простой запрос, чтобы убедиться, что всё работает. У нас он будет звучать как: «A man in a hat drinks coffee at a table in a cafe, room, cafe, man, blond, table, art, realism, 4k». Вбиваем в поле «Prompt» и жмём «Generate». Вот наш результат:

Как можно заметить, у нашего героя явные проблемы с конечностями и чертами лица. Это типичный артефакт нейросетей. Как исправить? Тут нам пригодится волшебное поле «Negative Prompt». Вбиваем туда следующее:
lowres, (bad hands), text, error, missing fingers, extra digit, fewer digits, cropped, (worst quality), (low quality), (normal quality), blurry, (ugly:2), (duplicate), (morbid), (((mutilated))), (out of frame), ((((extra fingers)))), (mutated hands:1), (poorly drawn hands:1), (poorly drawn face), (deformed, blurry), (bad anatomy:1), (bad proportions:1), (extra limbs), (cloned face), (disfigured), (gross proportions), (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), (fused fingers:2), (mutated fingers:2), too many fingers, (long neck), (scary face), (jpeg artifacts), (signature), (watermark), (username), (text), (poorly drawn legs)

Много текста? Определенно. Зато готовый результат выглядит куда более реалистичным и правильным. Все пальцы и черты лица на месте, анатомия в порядке, герой даже правильно держит чашку, жаль, что промахивается мимо неё. Как же так получилось?
У Stable Diffusion есть много разных настроек и опций. Некоторые влияют на скорость генерации, некоторые — на разнообразие результатов и их соответствие запросу. Два самых важных окна — это «Prompt» и «Negative prompt». И последнее, пожалуй, даже важнее.
«Prompt» (от англ. подсказка, запрос) — это команда, которую мы отправляем нейросети. С помощью набора тегов мы говорим ей «Хочу вот это!». Проблема в том, что нейросеть, пусть и обученная на языковой выборке в несколько миллионов слов и сочетаний, всё ещё плохо понимает, что от неё хотят.
Поэтому при запросе «Красный кубик на синем» она выдаст целую серию картинок, среди которых может быть как правильная, так и различный сюр — летающие кубики, кубик в кубике, красный кубик внутри синего, красный куб, торчащий из синего, и другие вариации.

Чтобы получить один из результатов, которые мы видим в интернете, потребуется несколько десятков попыток, так что если в первый раз у вас вышло что-то невнятное — всё в полном порядке.
Советуем для начала отправиться на PromptHero или Lexica.art. На этих ресурсах вы найдете тысячи готовых работ и запросов, с помощью которых они были созданы. Погуляйте по ним хотя бы минут двадцать, чтобы понять общую закономерность и то, как те или иные команды влияют на ракурс камеры, стиль или расположение персонажей.
А вот окно «Negative Prompt» говорит программе, как делать не надо. Указав здесь теги вроде «лишние пальцы», «уродливый персонаж», «кривое лицо», мы скажем программе, чтобы она особо тщательно следила за этими моментами.
Но финальная обработка вашего арта, конечно, будет производиться либо в PhotoShop, либо в окнах «imgtoimg» и «inpaint».
Сейчас давайте пройдемся по самым важным полям, которые пригодятся в первую очередь:
- «Prompt» и «Negative Prompt». Как сказано выше, это буквально запросы «Как делать надо» и «Как делать не надо».
- «Sampling Steps». Количество «шагов», через которые проходит запрос. Больше шагов — больше деталей, но чрезмерное количество может слишком изменить запрос и получится нечто невнятное. Оптимальное — 20-30, но всё зависит от модели и семплера («Sampling method»), который вы используете.
- «Sampling method». Отвечает за «метод» генерации картинки. Некоторые за меньшее количество шагов дают неплохой результат, другие просто изменяют стиль и акценты результата. Вот наглядное сравнение.
- «Width» и «Height». Разрешение готового изображения. Больше разрешение — больше время генерации и требования к видеокарте, а также больше «Sampling Steps». Так как многие модели обучались на картинках с разрешением 512х512, на больших изображениях детали могут дублироваться или мутировать. Для ландшафта это не так страшно, а вот вторая голова у персонажа — проблема. Галочка напротив пункта «Highres. Fix» частично помогает, но при большом количестве шагов мелкие детали все равно могут дублироваться.
- «Batch count» и «Batch size» похожи, но отличаются друг от друга на программном уровне. «Batch count» отвечает за, условно, количество нажатий на кнопку «Generate» (и лучше использовать это поле), а «Batch size» — за количество генераций за раз, высокое значение этого параметра приведет к переполнению памяти и вылету программы.
- «CFG Scale». Параметр «свободы» от запроса — насколько далеко программа может отходить от запроса и творить что-то своё рандомное. Базовое значение — 7. Можно поиграться, получив либо что-то совсем примитивное, либо сюрреализм. Но и интересные результаты тоже выдаются.
- «Save» сохраняет изображение на компьютер (по умолчанию включено автоматическое сохранение). «Send to img2img» отправляет в окно, где можно будет сгенерировать новый арт на основе готовой картинки. «Send to inpaint» перекинет картинку в модуль дальнейшей дорисовки отдельных фрагментов. «Send to extras» перенесет вас в меню апскейла и других дополнительных опций.
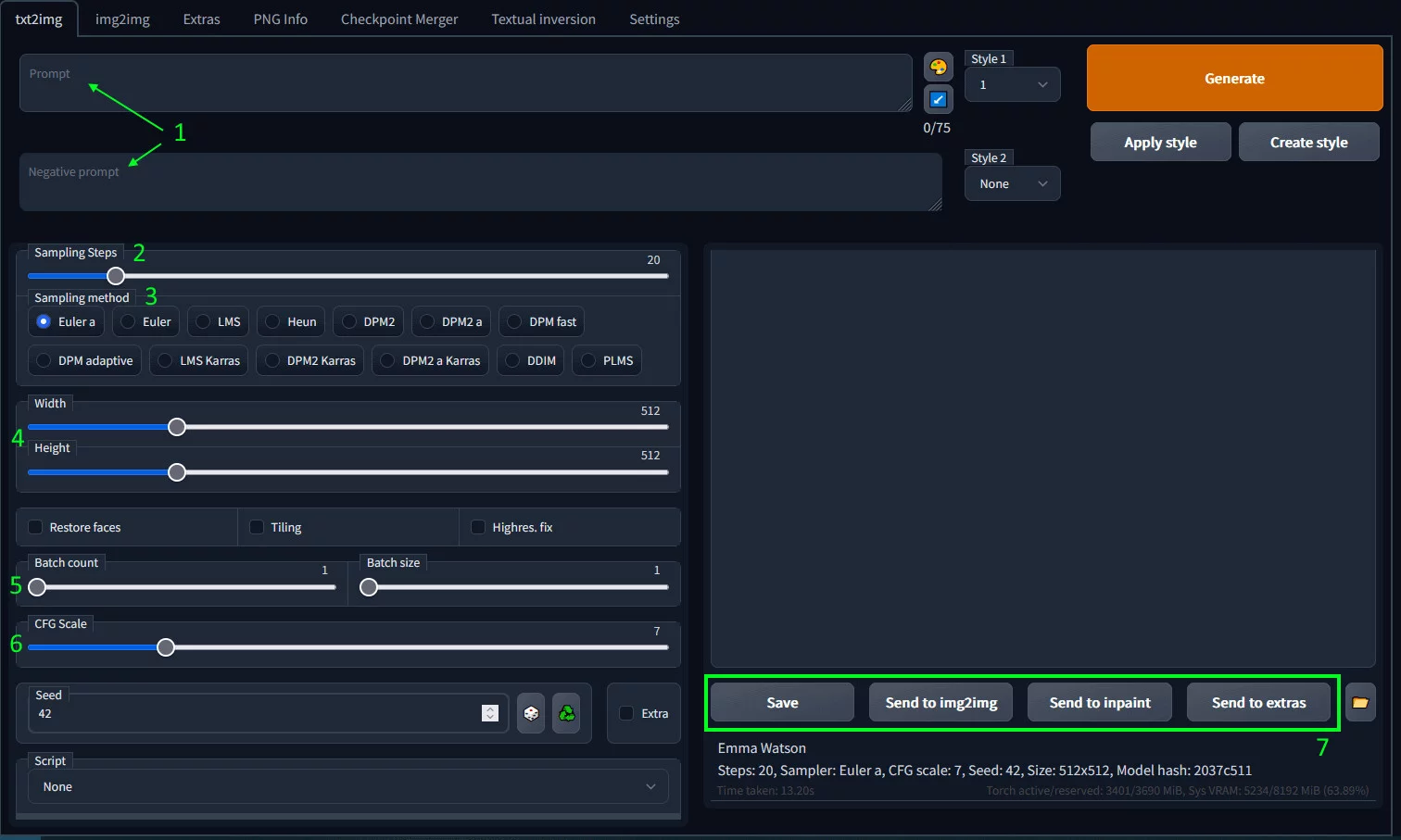
Другие поля отвечают за различные скрипты и удобство регулярного использования, вроде возможности сохранять часто используемые промты и стили.
Интервью с Nanashi Eltnum — опытным пользователем Stable Diffusion и автором множества гайдов
Знаний из предыдущей части будет достаточно, чтобы сгенерировать что-то похожее на настоящий digital art. Более подробные инструкции вы можете найти в группе NeuroFox.pro. Мы же связались с автором этих гайдов и расспросили её о тонкостях работы с Stable Diffusion.
VGTimes: Здравствуйте! Спасибо, что согласились уделить время. Расскажите немного о себе: чем занимаетесь, почему решили так погрузиться в тему нейросетей и арт-генераторов.
Nanashi Eltnum: Привет! Раньше я увлекалась рисованием, но потом забросила это на долгое время по личным причинам. Поскольку я творческий человек, вскоре перешла в 3D, которое помогло справиться с творческим выгоранием. Проходила различные курсы, вроде циклов по программированию игр на Unity от IGD, потом, с началом хайпа вокруг MidiJorney, решила попробовать погрузиться в эту область и, в общем-то, затянуло.

Я пока новичок, но очень много времени уделяю исследованию Stable Diffusion: читаю зарубежные гайды, тестирую, советуюсь с программистами. В общем, изучаю новую технологию и делюсь с такими же новичками полученным опытом.
Работаю именно с SD по той причине, что не удалось «дотянуться» до других крупных «сеток», вроде DALL-E 2 или MJ — сказывались ограничения в первом случае и неудобство работы в Discord вместе с трудностями в покупке подписки во втором. А вот онлайн-версия Stable Diffusion быстро полюбилась.
VGTimes: Как у человека, который пробовал себя в стольких сферах, может у вас есть идеи, почему вокруг столько шума о противостоянии художников и нейросетей? И используете ли лично вы результаты работы нейросети в прикладной сфере, не просто как развлечение?
Nanashi Eltnum: Что касается противостояния — всё дело в непонимании. Только и всего. Люди и художники не понимают, как это работает. Считают, что их вытеснят. Или что это украло их стиль, но тогда вопрос: почему они не быкуют на других художников, которые вдохновляются их работами?
Нейросеть уже доказала свою практическую пользу лично для меня. Например, некоторые из сгенерированных работ станут концептами для дальнейшей работы в 3D-редакторах и лягут в основу визуала для игры. Нейросеть выдаёт очень много интересных и крутых дизайнов, которые можно использовать, как набор референсов для представления визуала или доведения идеи.




Вот такие доспехи мы нарисовали с братом. Его изначальный скетч и идея, мой базовый шаблон, затем прогон через нейросеть, моя доработка и снова нейросеть для исправления деталей. Эти доспехи позже мы планируем воплотить в 3D и в них будет бегать персонаж брата.

Также у меня, буду честна, проблемы с представлением детальных фонов и локаций. Я больше по персонажам. Нейросеть и тут меня выручает, выдавая очень интересные идеи, которые потом можно воплотить в 3D.
Например, мне как-то нужна была церковь для одной из фэнтези-локаций. Брат ещё предложил в финальной версии добавить тематический витраж: в изначальной задумке игры сюжет крутился вокруг людей, потерявших родной мир из-за чудовищ. На витраже это рисовалось, как память о потерянном доме и о том, за что все они сейчас сражаются. Витраж хотели расположить на окнах, из которых на картинке идёт свет.

При правильном запросе эта штука может выдать тебе иллюстрацию для книги или идеи для иллюстрации, которые ты потом можешь отнести художникам. Как какой-никакой художник я тебе скажу, что ребятам будет куда легче опираться на визуальный референс.
А тут они ещё и уникальные, специально для тебя сделанные нейросетью. И никаких боёв за авторские права и часов поисков идеального варианта на Pinterest с подходящей лицензией. Красота?
Есть на моём опыте ещё очень милый пример. Мне его рассказал Mr4erk, основатель сервиса. Ему в ЛС написал человек, который использовал нейросеть в благотворительных целях. Ребята-инвалиды из детского дома генерировали нейросетью картинки, используя за основу свои рисунки. Судя по всему, ребятишки остались довольны, а это главное. Разве это не чудесно?
VGTimes: А что насчет устройства нейросетей? Знакомы ли вы с Stable Diffusion «под капотом»? Сумеете объяснить простым языком, как она работает?
Nanashi Eltnum: Под капот я не заглядывала, только что-то прям базовое, чтобы понимать как это работает и на что опирается. За этим я рекомендую обратиться к программистам, которые пишут такие сети и обучают их. Но даже по базовым знаниями могу сказать, что это очень интересно, но надо быть готовым к большому объёму информации.
VGTimes: Нейросети мучались с пальцами и глазами, но на ваших работах я не вижу с этим проблем. Неужели они научились их рисовать? Или всё зависит от точности запроса? Кстати, о запросах — можно ли получить своего персонажа или себя?
Nanashi Eltnum: От точности и качества запроса очень многое зависит, скажу это сразу. Но да, нейросети в целом, модели и алгоритмы постепенно становятся лучше, дорабатываются. Это неизбежный процесс для любого софта: вспомнить ту же MidiJorney в начале пути и сейчас, в четвертой версии.




Говоря о своём персонаже: опять же, все зависит от запроса и цели. В нашем случае ещё от качества шаблона, который ты сделаешь из фото. Но если прям конкретно нужен именно твой персонаж с конкретным дизайном, то можно подзапариться и обучить свою модель. Я находила такой урок, но пока только знакомлюсь с теорией.
Если же тебе хочется просто увидеть себя в аниме-стиле или стиле того же «Аркейн», то хватит твоей фотографии, отредактированной для работы в «нейронке», и грамотного запроса. Я подробно показывала примеры все в той же imgtoimg, и в теории описанные методы работают и для фотографий.
VGTimes: Как вы составляете запросы? Сначала делаете набросок? Или, к примеру, готовите обычное текстовое описание, а потом конвертируете его в промт?
Nanashi Eltnum: О-о-о, это интересная и долгая тема. Я рассказывала об этом в одной своей статье про генерацию персонажа, но повторюсь тут покороче.
Первоначально, если не знаешь, что хочешь, лучше потестить другие промты. На сервисе есть случайные примеры, можешь потыкать их и поразбирать теги.
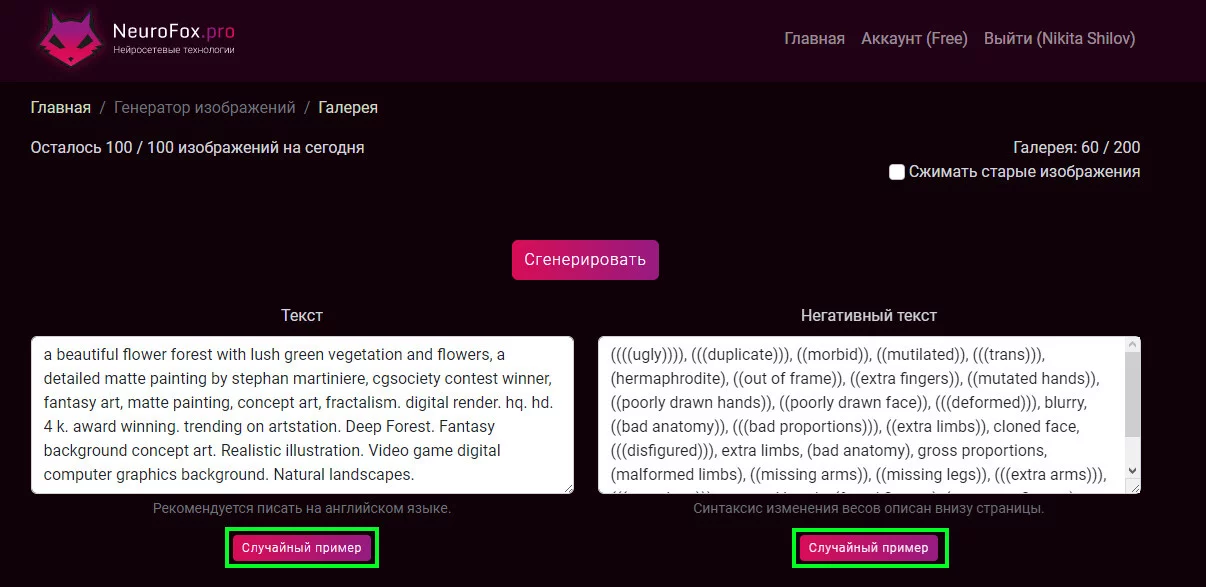
После тестов я сначала представляю персонажа, какие у него детали, какой у него стиль и т.д. Для уточнения тегов я захожу на danbooru, так как модели, которыми я пользуюсь, обучались на примерах с этого сайта и ему подобным. Также я опять смотрю примеры промтов, какая связка тегов лучше.
После составляю запрос, пишу дополнительные теги на улучшение глаз, рук, тела. Например, прописываю негатив (который я собирала по такому же принципу, исходя из своих нужд).
Запросы я пишу на английском. Если я не уверена или не знаю, как написать то или иное слово, использую переводчик DeepL — он, по моему мнению, работает лучше других.
Примеры промтов можно посмотреть опять же в рандоме на сервисе Neurofox.pro, или на сайтах-библиотеках. Иногда авторы на сайте pixiv ими делятся и рассказывают, как они сделали конкретную картинку. Плюс ребята в тематических чатах делятся своими промтами, или пишут, как лучше сделать что-то конкретное.

Ну и, собственно, тесты. Много тестов. Правки промтов, настроек, снова тесты. И так до идеала.
VGTimes: Как я понимаю, потом нужны программы апскейла для увеличения готовой модели. Они не портят качество и детали изображения?
Nanashi Eltnum: Если мы говорим про онлайн-сервис, то да, апскейл нужен. А портит он или нет зависит уже от программы, которой ты пользуешься и как её настраиваешь. К слову, в локальной SD есть и свой апскейл и улучшение. На сервисе, где я сейчас нахожусь, эти функции постепенно добавляются, а там уже посмотрим по тестам все.
VGTimes: Не пробовали работать в реализме? Сильно ли там всё отличается от аниме-промтов?
Nanashi Eltnum: Давай скажу так: я не люблю реализм по своим внутренним причинам. Одна из них личная, связана с весьма токсичными художниками. И это одна из причин, почему я когда-то забросила рисовать в принципе.
Плюс я всегда любила аниме-стилизацию за их выразительность, цвета, формы и так далее. А также допущения, которые в реализме технически невозможны и смотрятся ужасно. Да, реализм для меня слишком ограничен законами физики и логики. Но я восхищаюсь хорошими работами в таком жанре.






Стиль «Диснея» отбросила по другим причинам. Мультипликация у них хороша, но порой они делают слишком уж выразительную стилизацию. Хотя я с удовольствием смотрю старые мультики вроде «Красавицы и Чудовище» или «Белоснежки». Но, опять же, вкусовщина, я не продумываю своих персонажей под такой стиль.
Лично для меня аниме — это баланс между стилизацией, реализмом и ужасающим полётом фантазии многих японских авторов. Почему бы нет, собственно, ребята себя порой не ограничивают в фантазии, и мне это нравится. Опять же вспомним, чем для меня ограничен реализм.
Полуреализм, кстати, тоже нравится, когда сохраняются как стилизация, так и детально проработанные материалы. Как, например, у sakimichan и Zeronis (несколько их работ мы прикрепили ниже — прим. редакции).




По поводу промтов. Да, они отличаются в деталях, модели используются разные. Иногда один запрос на аниме-модели может не совсем корректно сработать на другой модели под реализм.
Но в целом нейросеть-то одна, поэтому вооружившись знаниями о конкретной модели, можно переделать промт. Иногда я так делаю, когда хочу посмотреть на персонажей в других стилях. А если ты хочешь пересесть с SD на MJ, то тут только тесты. Это две разные нейросети, хоть и в одном сегменте. Это как обратиться с запросом к разным художникам.
VGTimes: Как научиться «думать» промтом? Нет, правда — я не представляю, сколько нужно параметров прописать, чтобы, условно, создать «Дисней» или аниме-версию самого себя. Тут же столько моментов надо учесть — от негативного и позитивного текста до количества шагов и прочих штук.
Nanashi Eltnum: «Думать промтами» начало получаться само по себе, по мере проб и ошибок. Но для аналогии представь, что ты не знаешь имя и фамилию, но знаешь примерное описание того, что нужно найти. И идёшь в поисковик… Или на сайты, как danbooru, где по-своему описаны теги.
VGTimes: Что самое сложное в работе с нейросетью? Или, если освоишь принципы, ничего, кроме усердия, не нужно?
Nanashi Eltnum: Трудности возникают на моментах, когда модель, скажем честно, недостаточно обучена, чтобы понимать то, чего от нее хотят. Ей не хватает примеров из обучения, и она подбирает оптимальный вариант. Это человеческий фактор, автор модели не может учесть всего под все вкусы.

Второй фактор, то, с чем надо смириться, — нейросети не идеальные и они не заменят художников. Так что да, баги все равно есть. Они правятся либо более сложными запросами, либо настройками, либо инструментами, как imgtoimg. Либо ручками художника. Или программиста, если улучшается конкретно нейросеть или модель.
VGTimes: Как думаете, нейросети заменят художников? И сколько времени на это уйдет? Кажется, еще недавно о нейросетях особо никто не говорил, буквально за год такой скачок.
Nanashi Eltnum: Как я уже сказала, нейросеть не заменит художников. Честно, я очень сильно злюсь, когда вижу очередное видео об этом на Youtube ради хайпа. Арт-нейросети учатся на примерах, которые рисуются этими же художниками. По-хорошему и программироваться должны, исходя из мнения и советов как художников, так и пользователей.
Да и потом, нейросеть рисует красиво, да. Но если у неё, так уж получилось, нет примеров на твой запрос, она это не нарисует. Да и художники — люди творческие, и именно такие люди, а так же дизайнеры, фотографы, программисты, 3D-моделеры, блогеры, писатели и другие крутые творческие ребята, задают те самые креативы, за которыми потом и наблюдает весь мир.





Вспомним, сколько было ора по поводу 3D-графики и графических планшетов у тех же художников. Мол, как же так, читерство, собирать базу в программе и дорисовывать!
А теперь на некоторых курсах буквально учат художников базису работы с 3D-софтом, и чуть ли не в каждую компанию нужен и тот, кто владеет планшетом или программами по рисованию. Почему? Потому что это ускоряет процесс работы в разы.
А с появлением планшета ещё не значит, что отпала надобность в тех, кто рисует материалами. Даже наоборот, люди, любящие картины красками, остались, спрос есть. Я восхищаюсь теми художниками, которые изучают пигменты красок, тратятся на те же материалы, бумагу и рисуют по-традиционному.
Так же и с нейросетью. Воспринимать её нужно как инструмент и помощника для ускорения процесса работы.

Пройдет ещё много времени на совершенствование этой технологии, даже не смотря на технические прогрессы и прорывы. Но все равно останутся любители классики в виде картин красками или любители картин именно художников, а не нейросети. Ностальгия — штука коварная, как и привычки, от них не избавишься.
Но почему бы не забить на материалы и то, как это сделано и кем? Можно просто наслаждаться результатом.
VGTimes: Может, есть какие-нибудь интересные мысли, которыми вы хотели бы поделиться?
Nanashi Eltnum: Перестаём хандрить и видим позитивные стороны появления такой крутой технологии, ставшей доступной людям. И не слушаем других любителей хайпа ради хайпа.
Помните, если вы действительно хороши в своём деле и развиваетесь, у вас, как специалиста, будет спрос. Это везде работает, не только в художественной сфере. А нейронка может вам помочь развить ваши навыки лучше. И покидать референсов для вдохновения, куда без этого.



И вот вам мой личный пример. Как я говорила выше, из-за сложившихся обстоятельств, мне было буквально противно рисовать. Вот настолько все плохо, особенно из-за вылившейся из этих обстоятельств сильной депрессии с выгоранием.
Но, благодаря нейросетям, я все-таки беру в руки стилус и открываю графический редактор. Что-то подправить, нарисовать шаблон, снова поправить, посидеть и покайфовать с результата.
Как обучить Stable Diffusion чему-то новому?
Мы уже делали гайд о том, как нарисовать свой портрет с помощью онлайн-версии Stable Diffusion. Вы можете найти его здесь. Процесс обучения на локальной версии не сильно отличается. Для этого внутри программы есть вкладка «Train», но разработчики предупреждают, что это достаточно сырая функция, результат может быть далёк от идеала.
Также перед началом процесса выберите модель, которую будете «дообучать» в поле «Stable Diffusion checkpoint» в шапке страницы. Это важно, поскольку полученный концепт будет работать стабильно на той модели, на которой его дообучали и может давать непредсказуемые результаты в других случаях.
На примере ниже модель обучили новому тегу в Waifu Diffusion 1.2. Первое изображение — результат генерации на модели WD1.2, второе — тот же промт, но при включенной модели Stable Diffusion 1.4.


Также вам понадобится действительно много видеопамяти — GTX1660S автора с задачей так и не справилась, вылетая с ошибкой «CUDA out of memory». Если вы обладатель рекомендуемого количества видеопамяти (8-10 Гб), вот подробная инструкция по дообучению модели:
- Для начала подготовьте набор фотографий желаемой модели-концепта — своего лица, любимого героя игры. Мы взяли в качестве примера Ян Фей из Genshin Impact и наделали с ней скриншотов. Чем больше — тем лучше, но хватит и 10-15 фотографий для минимального результата.
- Обработайте их в онлайн-редакторах или в Photoshop, обрезав лишнее так, чтобы получилась квадратная картинка с объектом в центре.
- Перейдите на вкладку «Train», выберите пункт «Preprocess images». Здесь мы подготовим изображения к обучению. В строку «Source directory» вставьте путь до папки с отредактированным изображениям. Создайте ещё одну папку и пропишите её путь в «Destination directory». Сюда сохранятся обработанные изображения. Можно также поставить галочки напротив «Create flipped copies», это создаст больше вариаций для обучения, отзеркалив фото.
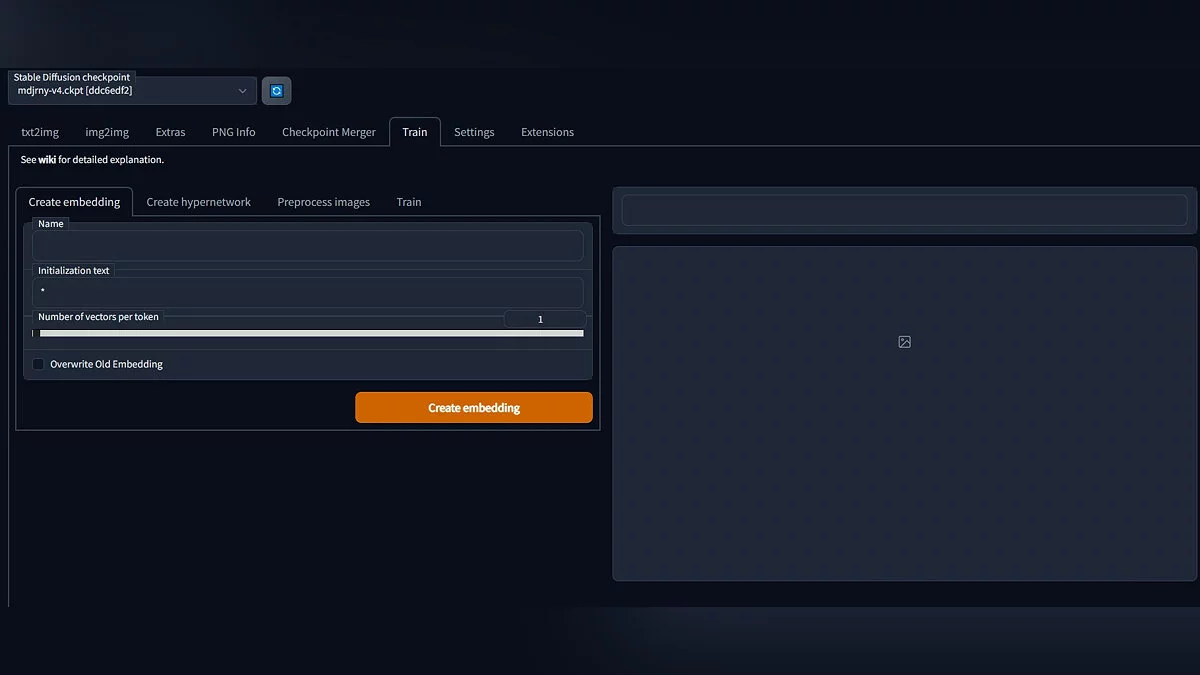
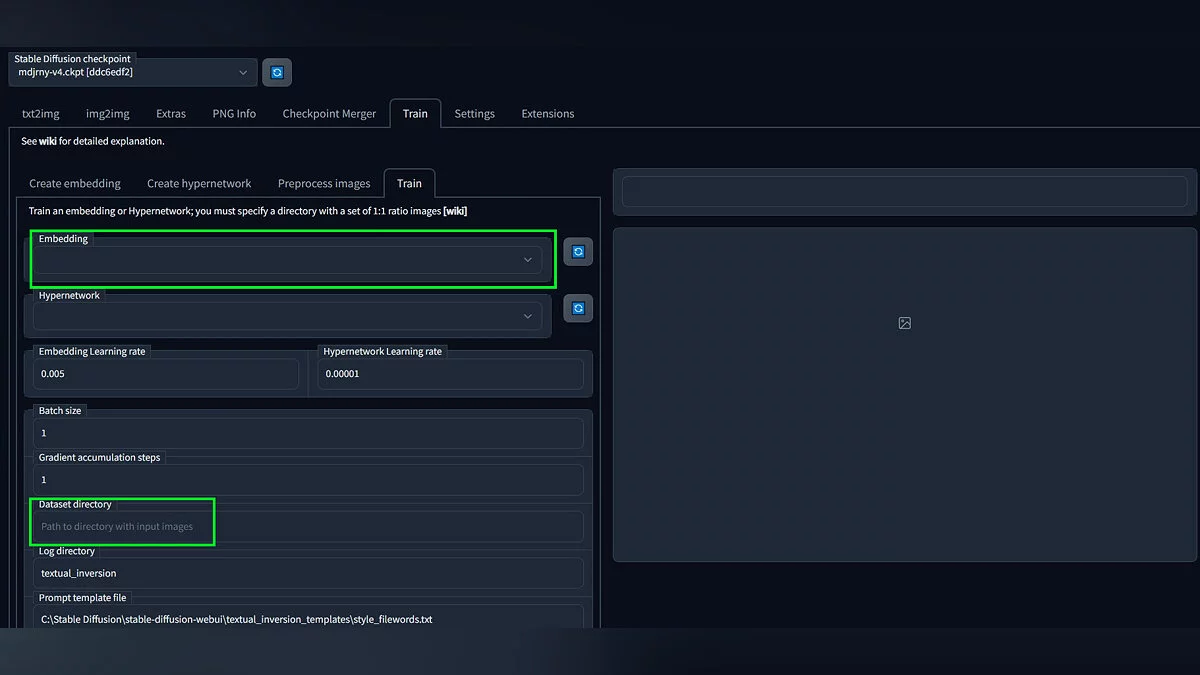
- На вкладке «Create embedding» создайте саму модель. Поле «Name» отвечает за название готового файла, «Initialization text» — за то, какими словами мы будем «вызывать» нашу Ян Фей во время генерации. С пунктом «Number of vectors per token» всё интереснее: чем больше это значение, тем больше информации о предмете получится уместить в файл, но и в самом запросе оно «съест» такое же количество слов. Напомним, что Stable Diffusion не обрабатывает больше 75 тегов в поле «Prompt». Кроме того, чем больше это значение, тем больше понадобится изображений для обучения. Достаточно примерно 4-8 векторов для приличного результата. После нажмите «Create embedding»
- Перейдите на вкладку «Train», в поле «Embedding» выберите созданную концепцию, в поле «Dataset directory» укажите местоположение обработанных в пункте 3 изображений. «Max steps» отвечает за то, сколько шагов будет обрабатываться модель. Больше — лучше и дольше, 19500 должно хватить для первых результатов. Остальные настройки пока можно оставить по умолчанию. Для начала генерации нажмите кнопку «Train Embedding».
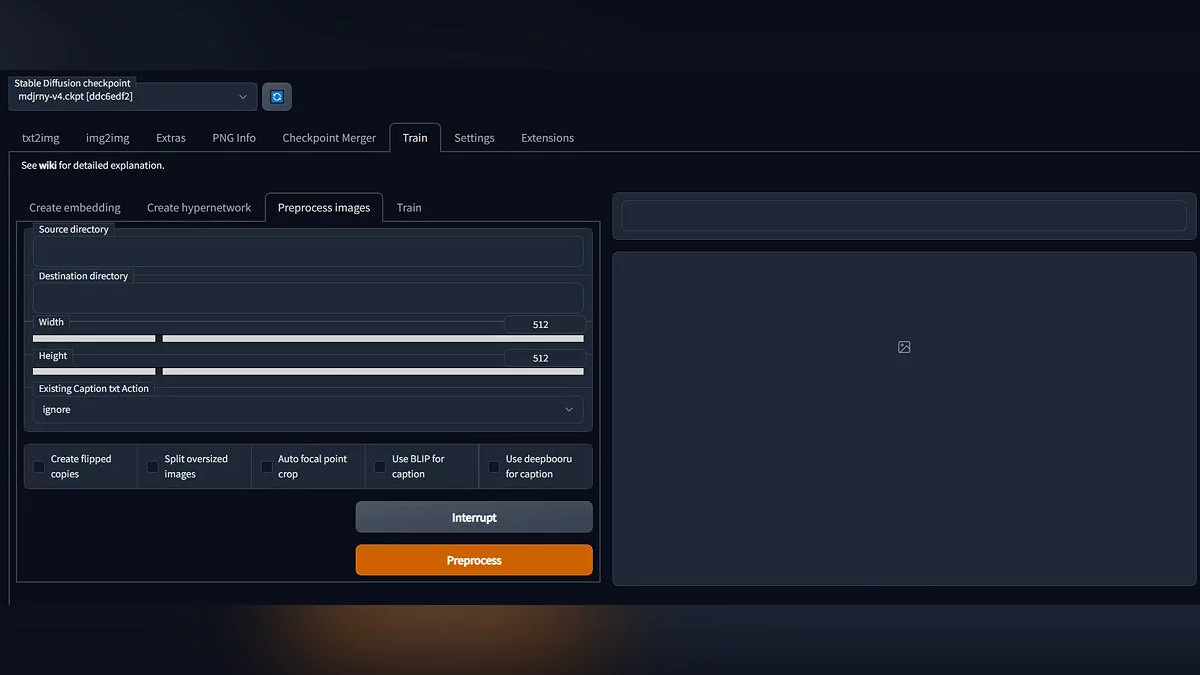
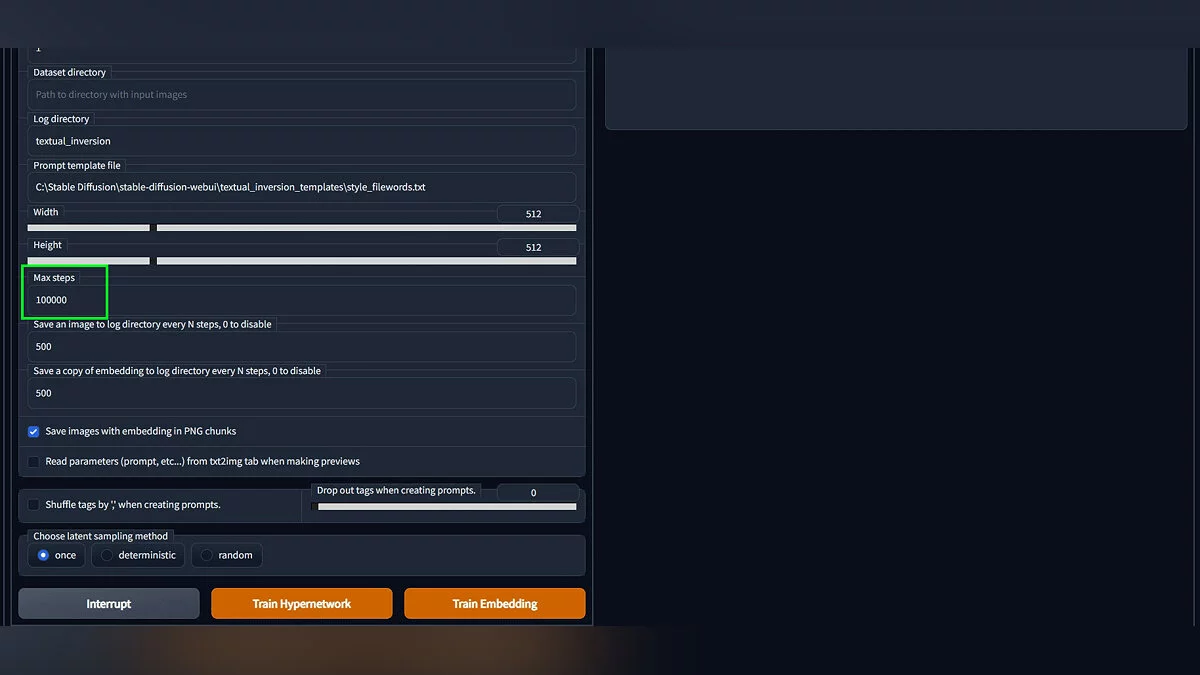
Если в консоли через некоторое время не появились сообщения об ошибках, процесс запущен. Дообучение модели — процесс не быстрый и займет минимум 3 часа. Всё это время видеокарта будет загружена по полной. Более подробную документацию о настройках, правилах и примеры дообучения можно найти на официальном GitHub функции.
В итоге мы получим файл с названием модели и расширением .pt, который будет сохранен в папке «…stable-diffusion-webui\embeddings». Туда же можно поместить и скачанные из интернета концепции. Здесь, к примеру, можно найти концепции Among Us, лиц из Arcane и стилизацию под Fortnite.
Другие фишки Stable Diffusion: лучшие модели, NSFW-контент и возможности программы
Stable Diffusion — гибкий и мощный инструмент, возможности которого можно разбирать в десятках гайдов. Но вот несколько особенностей, которым мы хотим уделить отдельное внимание.
Десятки различных моделей
На основе Stable Diffusion были созданы десятки различных моделей — от копии MidiJorney v4 до генератора аниме-изображений и стилизации под Disney. Самые популярные и «умные» можно найти здесь. А здесь хранятся модели для «ценителей», так что будьте осторожны — как это часто бывает в Интернете, многие модели сосредоточены на NSFW-контенте.
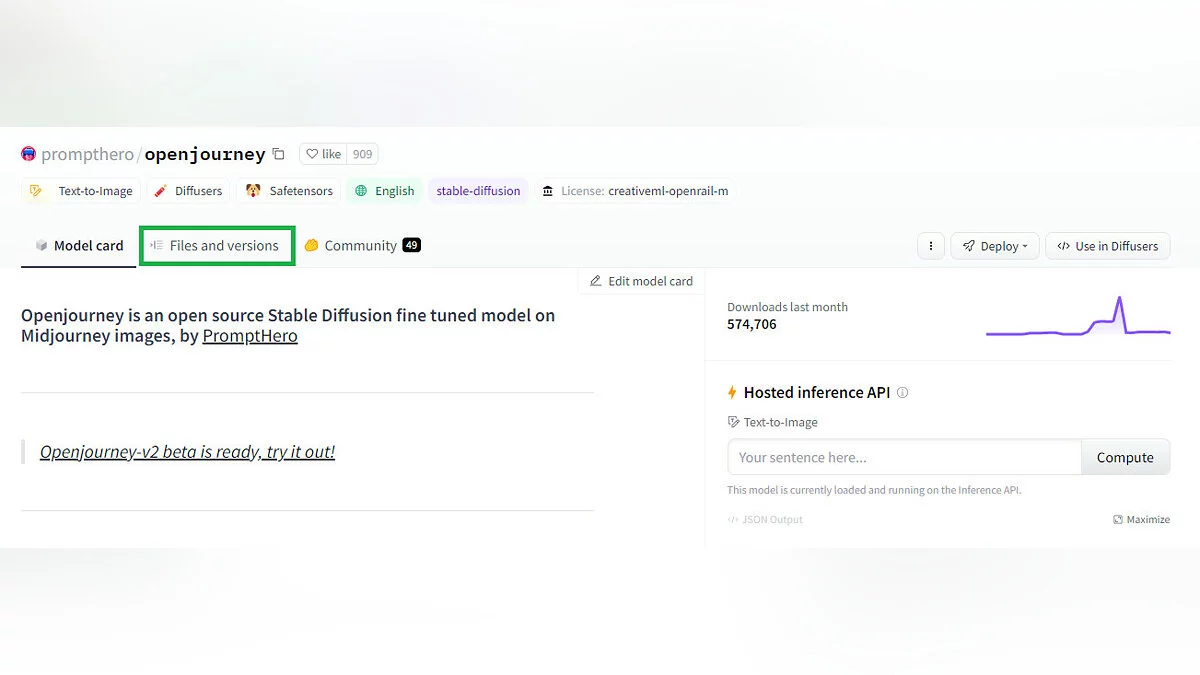
По ссылкам ниже вы перейдете на страницы моделей на Hugging Face. Там можно найти примеры работ, теги-активаторы и другую информацию. Чтобы скачать модель, перейдите во вкладку Files and versions и скачайте файл с расширением «.ckpt». Если их несколько, ориентируйтесь на версию и размеры файла.
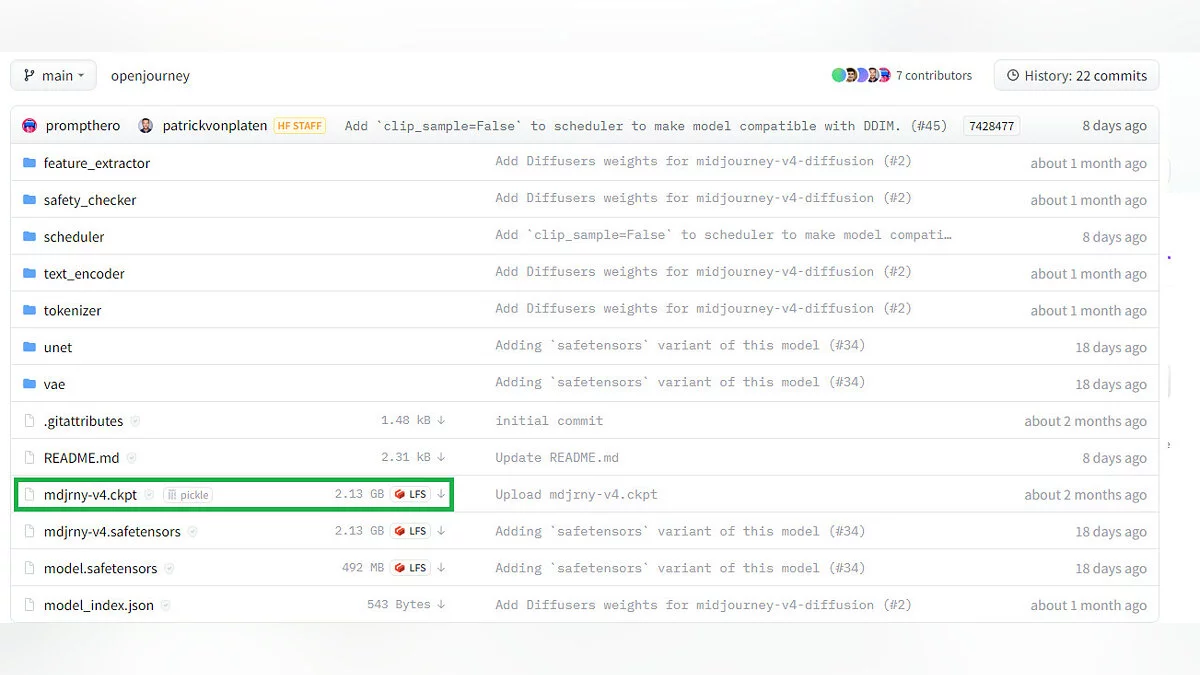
Новые модели почти всегда устанавливаются в папку «stable-diffusion-webui\models\Stable-diffusion» и имеют формат «.ckpt», например, «Anything-V3.0.ckpt». После скидывания модели в нужную папку не обязательно перезапускать программу, достаточно нажать на значок  и выбрать в списке «Stable Diffusion checkpoint» новую модель. Спустя пару минут модели загрузятся, и она будет готова к работе.
и выбрать в списке «Stable Diffusion checkpoint» новую модель. Спустя пару минут модели загрузятся, и она будет готова к работе.
Также обратите внимание, что уникальный стиль моделей необходимо активировать вручную, прописывая в промт уникальный тег, например «arcane style» или «1girl». Тег можно найти на странице скачивания модели вместе с примерами готовых работ.
Вот несколько интересных моделей, которые мы нашли:
Stable Diffusion 1.5 — базовая модель, способная на всё по чуть-чуть. Подходит для реализма и «комиксов», но многое зависит от точности запроса. Отличный первый шаг в изучении нейронок и понимании принципа построения промтов.




NovelAI, Anything 3.0 и Waifu Diffusion в целом схожи между собой, но обучались на разном количестве изображений и с разными настройками. Лучше протестировать каждую из них и выбрать понравившуюся. Локальную версию NovelAI предстоит отыскать самостоятельно.
Anything 3.0 лучше справляется с генерацией классических аниме-картинок, NovelAI неплохо знает NSFW-анатомию персонажей, а Waifu Diffusion понимает запросы по играм и аниме, а также рисует не только аниме, но и классический digital-art.



Openjourney обучена на изображениях от MidiJorney. У неё получается копировать картинки этой нейросети. Так что если вам не достаточно бесплатных запросов в Discord, просто скачайте эту модель и пробуйте столько, сколько захочется.




Analog Diffusion тренировалась на аналоговых фотографиях и теперь выдает фотореалистичные изображения людей. После небольшой доработки в Photoshop путем наложения легкого шума, результат почти не отличить от старых фотографий.

Также стоит упомянуть наличие небольших моделей, натренированных под конкретный стиль. Arcane Diffusion, как ясно из названия, выдает результаты, стилизованные под мультсериал Arcane. Cyberpunk Anime Diffusion старается подарить нам арты в стилистике Cyberpunk: Edgerunners. Результаты Classic Animation Diffusion похожи на кадры из старых мультфильмов Dysney, а вот Mo Di Diffusion выдает героев и антуражи, смахивающие на современную 3D-мультипликацию компании. Ну а Redshift Diffusion просто стилизует запросы под результаты 3D-рендеров.





NSFW-фильтра, как такового, здесь нет
В той версии программы, которую мы установили по инструкции выше, нет NSFW-фильтра, но результат запроса зависит от моделей, которые вы активируете.
Некоторые из них, вроде Stable Diffusion, не обучены нужным тегам и не натренированы на достаточном количестве NSFW-контента, в то время как другие наоборот сосредоточены вокруг этой темы.
Поэтому если вы не получили желаемый результат, проверьте установленную модель, выставленные настройки и сгенерируйте несколько запросов по чужим промтам.
Апскейл и исправление лиц
У созданных изображений низкое разрешение — 512х512 пикселей. Чтобы получить готовый результат в высоком разрешении, достаточно перейти на вкладку «Extras» или на вкладке с результатом нажать на кнопку «Send to extras».
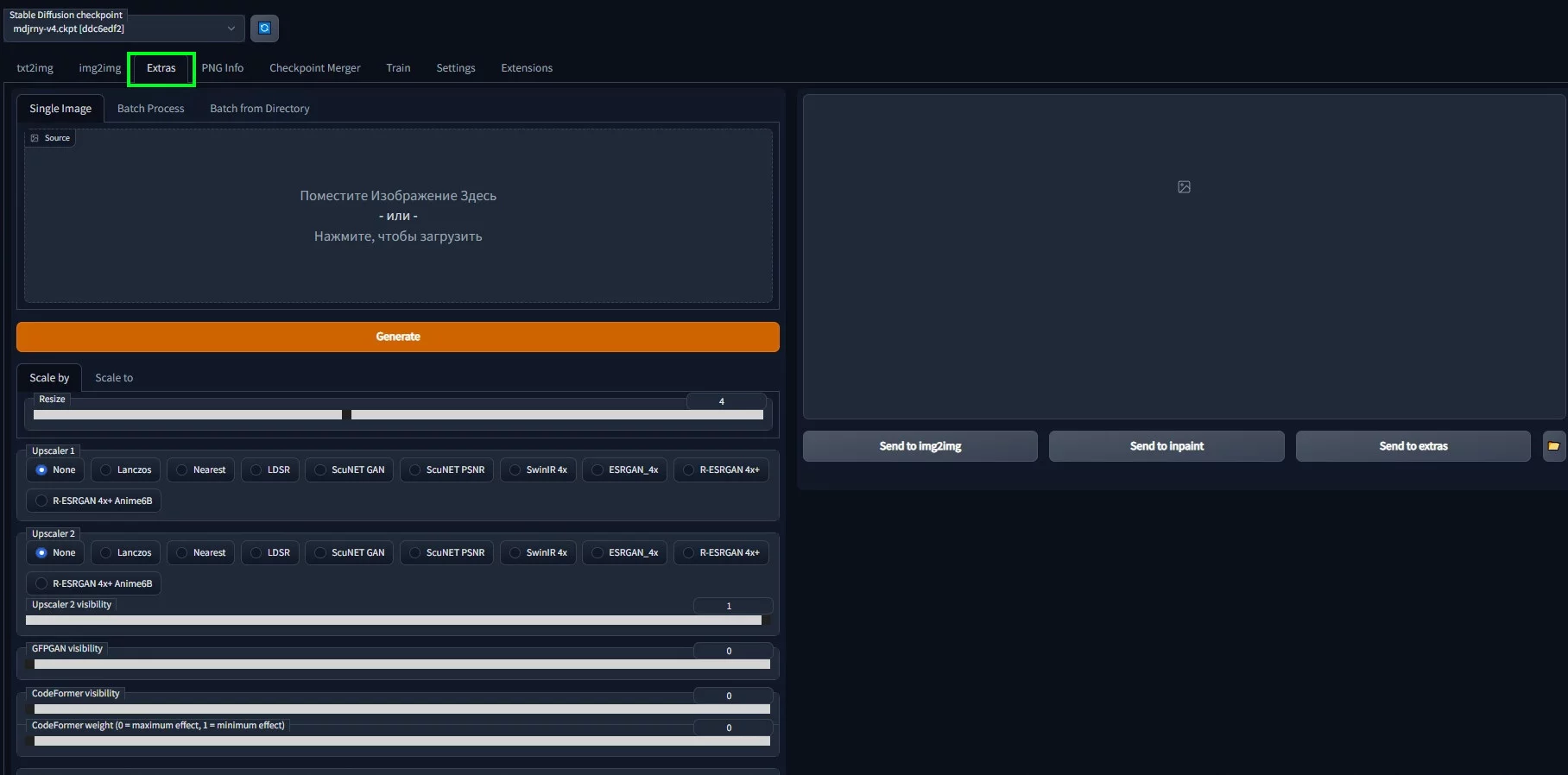
Здесь вы можете увеличить изображение в определенное количество раз («Scale by») или до определенное разрешения («Scale to»). «Upscaler 1» отвечает за сам апскейл, а «Upscaler 2» добавляет детали или убирает лишние, его «сила» настраивается ползунком «Upscaler 2 visibility».
Наконец, ползунки «GFPGAN visibility» и «CodeFormer visibility» улучшают лица. Codeformer отвечает за качество кожи, а GFPGAN исправляет взгляд. Для лучшего эффекта стоит их комбинировать, но, если переборщить, лицо на изображении покроется «тонной косметики» или заработает новые артефакты.
На что способна нейросеть будущего? Интервью с командой NeuroFox.pro
Прорыв, который совершили нейросети за последний год, заставил нас задуматься о том, на что способна эта технология. С этим, а также со множеством других вопросов, мы отправились к основателям сервиса нейросетевых технологий NeuroFox.pro — руководителю проекта Семену Шейному и ведущему программисту под ником Mr4erk.
VGTimes: Как начиналась работа на NeuroFox.pro?
Семен Шейн: Пожалуй, началось всё с того, что пара наших разработчиков увлекались искусственным интеллектом — писали чат-боты, исследовали технологию, пробовали разные инструменты. А рынок подсказал нам бизнес-идею и способ направить интерес к нейросетям всей компании в нужное русло.

Над NeuroFox сейчас работает группа энтузиастов, которые знакомы друг с другом долгое время — друзья, коллеги по работе, люди с похожими интересами. С ними я уже работал над другими коммерческими проектами. И когда появилась возможность, решил собрать команду для работы над новым проектом. Люди опытные, кто-то трудился в крупных коммерческих IT-структурах, кто-то вкалывает в белорусском аналоге Сколково.
VGTimes: Как считаете, почему именно на «картиночных» сетках эта тема так завирусилась?
Семен Шейн: Удачное стечение обстоятельств. В первую очередь — появилось огромное количество свободных мощностей на фоне падения криптовалют. Тысячи видеокарт начали простаивать, а их владельцы либо сливают эти активы, либо начинают сдавать в аренду, потому что это выгоднее, чем майнить.
Мы решили воспользоваться возможностью и начали потихоньку брать оборудование, чтобы использовать для своих целей. Придумали это не мы, сейчас многие компании так поступают.
Нейросети начали развиваться не год и не два назад, но тогда процесс шел медленно — мощностей катастрофически не хватало. Сейчас дефицита нет, скорее профицит. Поэтому мы, как и многие другие энтузиасты, решились на реализацию нашей старой идеи. До этого мы что-то тестировали, пробовали нейронки, экспериментировали, но достаточных мощностей не было. Ну а «картиночные» нейросети дают наглядный и увлекательный результат.



VGTimes: То есть, громко выразимся, крах одной технологии, криптовалют, дал толчок другой технологии — нейросетям?
Семен Шейн: В целом верно, но обратная зависимость тоже работает — очередной «бум» майнинга может вызвать у сервиса серьезные проблемы, ведь мощностей снова станет не хватать.
Нам очень помогают энтузиасты, среди пользователей, которые, помимо использования сервиса, ещё и предоставляют свои мощности для поддержания работы NeuroFox.pro и повышения производительности сервиса.
Да и опять же, другие типы нейросетей, вроде DeepFake, были скорее развлечением. Их никто не рассматривал в качестве серьезного инструмента. Я и сам пару раз пробовал всякие сетки, скачивал, развлекался, кидал результаты друзьям и удалял.
Здесь же мы имеем просто колоссальный потенциал развития. Берем, к примеру, игровую индустрию и тех же дизайнеров персонажей. У них вечно проблемы с тем, чтобы найти интересные референсы и создать уникального персонажа или что-нибудь ещё.





Но сейчас они могут черпать идеи из работ нейросетей, получая при этом абсолютно уникального персонажа. Им достаточно преобразовать результат, отредактировать и вот — NPC готов. Это не редкость, я слышал о паре проектов, которые были полностью «нарисованы» нейросетями.
Сейчас этой технологией пользуются в основном художники, но многие предприниматели ищут методы использования нейросетей для решения прикладных задач. Раньше, к примеру, создание логотипа компании требовало серьезных вложений и специалистов. Сейчас достаточно вбить в программу тридцать-сорок слов, потом всё это немного доработать — и готово, вот тебе 20-30-50 вариантов логотипов.
VGTimes: А вы, как администратор и управленец, насколько разбираетесь в нейросетях? Понимаете, как это работает «под капотом»?
Семен Шейн: Относительно. Я кодингом не занимаюсь. Больше слежу за вектором развития, занимаюсь переговорами со сторонними коммерческими структурами, решаю вопросы с мощностями и юридическими тонкостями. В общем, вместе с Mr4erk собираю ребят вместе и организую работу.
VGTimes: Можно ли объяснить работу нейросети простыми словами? Может, есть хорошие материалы, который «на пальцах» объясняют процесс работы? Многие знают про «веса», «нейроны» и другие составляющие, но мало кто осознает принцип работы.
Mr4erk: Про работу нейросети простыми словами уже много где рассказано, и я не думаю, что скажу что-то новое. Нейросеть можно описать как черный ящик с кнопочками с одной стороны и лампочками с другой, а также набором связей и весов между ними для получения максимально предсказуемых результатов горения лампочек при нажатии определенных кнопочек.



VGTimes: В чем основная сложность в работе с нейросетью на программном уровне?
Mr4erk: Тут вопрос — на каком программном уровне. Самое сложное — это непосредственно написание алгоритмов подготовки данных для нейросети. Кодировать тот же текст, изображения в понятный набор данных за нейросети и обратное — раскодировать уже полученные данные в понятные для конечного пользователя объекты: текст, изображения и тому подобное.
VGTimes: А что до тренировки концепций и новых тегов?
Mr4erk: Самое сложное в создании и обучении нейросети — это сбор и разметка данных для обучения, это колоссальная и рутинная работа. Очень выручают различные имиджборды, имеющие подробные описания изображений. Очень хорошо в этом плане продвинулось аниме благодаря danbooru и подобным сайтам, где авторы довольно подробно описывают тегами свои работы.



В домашних условиях сейчас вполне можно дообучить нейросеть на десятке своих фото с привязкой к определенному слову. И при запросе с этим словом получать изображение себя в различных стилях, которым уже обучена нейросеть.
VGTimes: Как понять, что ты запрограммировал хороший модуль для нейросети? Только путем пробной генерации изображений?
Mr4erk: Ну, если вопрос об обучении модели — да. Тут методом проб и ошибок, промежуточных результатов. Нужно постоянно проверять, что у тебя получается.
VGTimes: Что нужно знать, чтобы самому делать нейросети?
Mr4erk: Вопрос неоднозначный. Написать простенькую «нейронку» с нуля или просто скачать готовую библиотеку, почитав про основы, может каждый, кто хоть немного знаком с программированием.
Если же вопрос касается создания модели (весов), то тут даже программирование особо знать не надо: уже есть готовые плагины к интерфейсам для работы с Stable Diffusion, где нужно только собрать и разметить датасет, подобрать параметры для обучения/дообучения модели, запустить, ждать, проверять промежуточные результаты. Но на текущий момент для обучения необходимы довольно мощные видеокарты.

VGTimes: Stable Diffusion — единственный проект с открытым кодом? Лучше ли он, чем MidiJorney? Что думаете о других сетках?
Mr4erk: Насчёт других нейросетей с открытым исходным кодом много сказать не могу, так как не встречал их.
Если сравнивать Stable Diffusion, MidiJorney и ту же DALL-E 2, то непосредственный плюс SD — это ее открытость и богатый функционал. Уже есть куча оболочек, интерфейсов, но заточены они в основном к работе локально и на компьютерах с видеокартами не ниже GTX1080/2070/3060.
Ещё большой плюс — публичные открытые модели. Сейчас на просторах сети вполне можно найти необходимые модели почти на любой вкус.
MidiJorney выдает результат несколько лучше SD, но тут часть секрета в том, что это корпоративный продукт. Из минусов могу отметить лишь бедный функционал и возможность работать только через Discord.
Результаты работы DALL-E 2 я видел реже. Могу отметить , что у нее упор больше на реалистичность, а ещё схожий с SD функционал в плане рисования.
Семен Шейн: Скажу о рынке и известности. Всё происходит постепенно. У MidiJorney был выигрыш во времени — люди привыкли к этому ресурсу, даже если он выходит чуть дороже, даже с учетом того, что авторского права у авторов, сгенерировавших тот или иной запрос, нет. Эта нейросеть куда дольше гремела в социальных сетях.
Но постепенно, даже если смотреть по хештегам, рынок начинает двигаться в сторону популярности Stable Diffusion.
VGTimes: Нейросети мучались с пальцами и глазами, но в работах Nanashi я не вижу с этим проблем. Неужели они научились их рисовать? Или всё зависит от точности запроса?
Mr4erk: Если говорить о проблеме в целом, то для нейросетей руки и пальцы — больная тема в связи с большой сложностью самой модели руки и миллионов возможных комбинаций.
Ну и, в первую очередь, подобные нейросети умеют хорошо рисовать, но не умеют считать количество нарисованных объектов. С подобными проблемами я сталкивался и в текстовых нейросетях. Они плохо дорисовывают скрытые чем-либо объекты.
Про работы Нанаши — во-первых, это большая выборка изображений. Во-вторых, это кропотливая детальная работа с промтом, как позитивным, так и негативным. Нейросети можно указать на вещи, которые получились плохо: плохую анатомию, лишние пальцы, страшное лицо и прочее. И загнать все недостатки в негативный промт.


В-третьих, высокое качество анимешных и смешанных с ними моделей, так как на различных площадках вроде danbooru художники тщательно прописывают все теги, что очень хорошо сказывается на качестве обучения и, соответственно, результате.
Семен Шейн: Да, при грамотном составлении промта можно получить изображение без артефактов, которому не потребуется доработка. Мы не одни такие — другие нейросети тоже получают обновления, которые решают перечисленные проблемы. И у них даже проще — появляется отдельная галочка, условно говоря, «убрать артефакты», «пять пальцев», «два глаза».
VGTimes: Планируете вводить подобное?
Семен Шейн: Да, определенно. Мы сейчас работаем над интерфейсом, чтобы сделать его удобнее для пользователя. Стоит сказать, что основная масса проблем, с которым сталкивается пользователь нейросетей, заключается в перегруженном и не очень понятном интерфейсе.
Мне двадцать семь. Ради интереса, когда мы выкатили первую версию NeuroFox, я попытался самостоятельно во всем разобраться и попросил ребят-программистов мне не подсказывать. Чтобы изначально понять, как работает интерфейс нашего ресурса, мне понадобилось пять часов, прежде чем я сгенерировал что-то адекватное. А я более или менее разбираюсь в этой теме.
Как-то я попросил одного знакомого «за сорок», работающего в графике, разобраться в интерфейсе: написал, предложил, выдал аккаунт. Человек не разобрался даже за неделю. Он сказал, что честно пытался, пробовал, но никак не получилось.
И большая часть людей, которая потенциально могла стать клиентами нашего сервиса, сталкивается с похожими проблемами. Даже по нашей статистике — многие заходят, пробуют, у них не получаются, они уходят.
Это основная проблема. Ни у одной нейросети сейчас нет понятной инструкции или решения, чтобы потенциальный пользователь мог разобраться за пару минут со всем. При этом мы можем так сделать, но тогда пользователь будет ограничен небольшим количество настроек.
И тут выбор — ты либо делаешь понятный, но ограниченный в возможностях интерфейс, либо даешь полный инструментарий, и человек в нём теряется. Поэтому одна из наших основных задач — написать понятный и удобный интерфейс. Но пока ни у кого это не получилось.

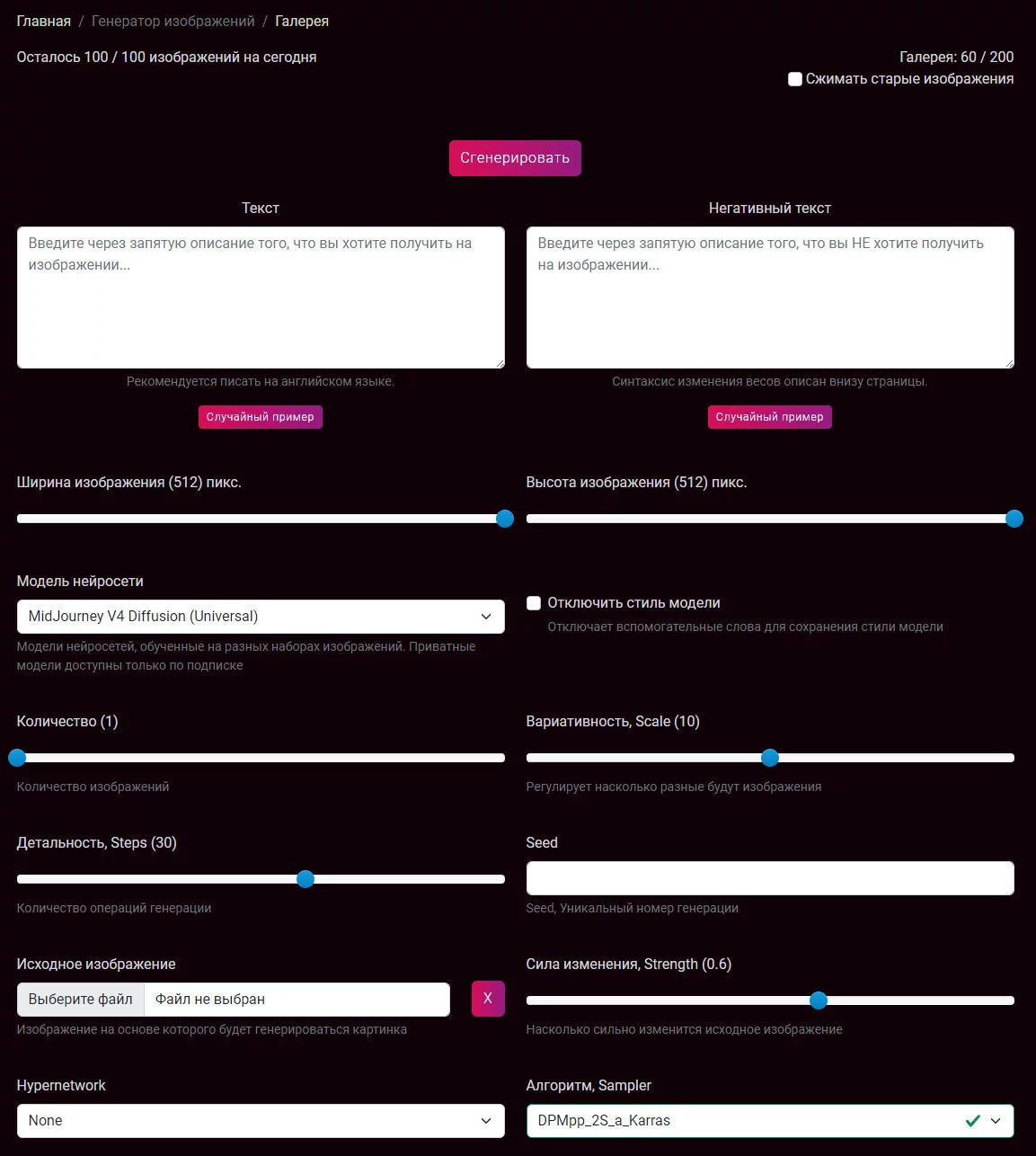
Хотя мы уже, к примеру, реализовали вариант рандома — жмёшь кнопку «Случайный пример», тебе выдается один из готовых запросов, и ты смотришь на результат. Это, при базовом знании английского, хотя бы даёт возможность понять, от чего отталкиваться.
Скорее всего, мы разделим сервис на две версии — вариант для профессионалов и для развлечения. В первом случае — максимум настроек и гибкости. Во втором — только основные опции, которые потом можно переслать друзьям.
VGTimes: Возможно ли получить своего персонажа? Например, загрузить несколько фото и сделать свою киберпанк- или аниме-версию?
Mr4erk: Вполне. На YouTube много гайдов об этом. Можно взять интересующую модель, дообучить ее на основе своих фотографий и их описания.




VGTimes: На сайте видел, что вы используете 3060 для генерации и сейчас собираете средства на 4090, но после нашего разговора уже сомневаюсь, что среди ваших ресурсов лишь одна RTX 3060. Как дела обстоят на самом деле?
Семен Шейн: На сегодняшних день у нас, грубо говоря, работает в сумме 70 видеокарт. Примерно 15 карт — наша собственность, которую мы периодически включаем в работу сервиса. Всё остальное — это, скажем так, меценаты, которые делятся мощностями.
VGTimes: Да, кажется, моей 1660S не хватит для комфортной работы с Stable Diffusion.
Семен Шейн: Зависит от выставленных настроек. Разрешение, количество ходов — можно генерировать как те же 320х320, а можно 1024х1024. Количество затраченного времени будет отличаться в разы. Зависит и от некоторых настроек. Одна и та же картинка с минимальной разницей настроек может генерироваться как пять секунд, так и 55 минут. А можно задать генерацию такой картинки, которая будет создаваться пять дней на одной карте.
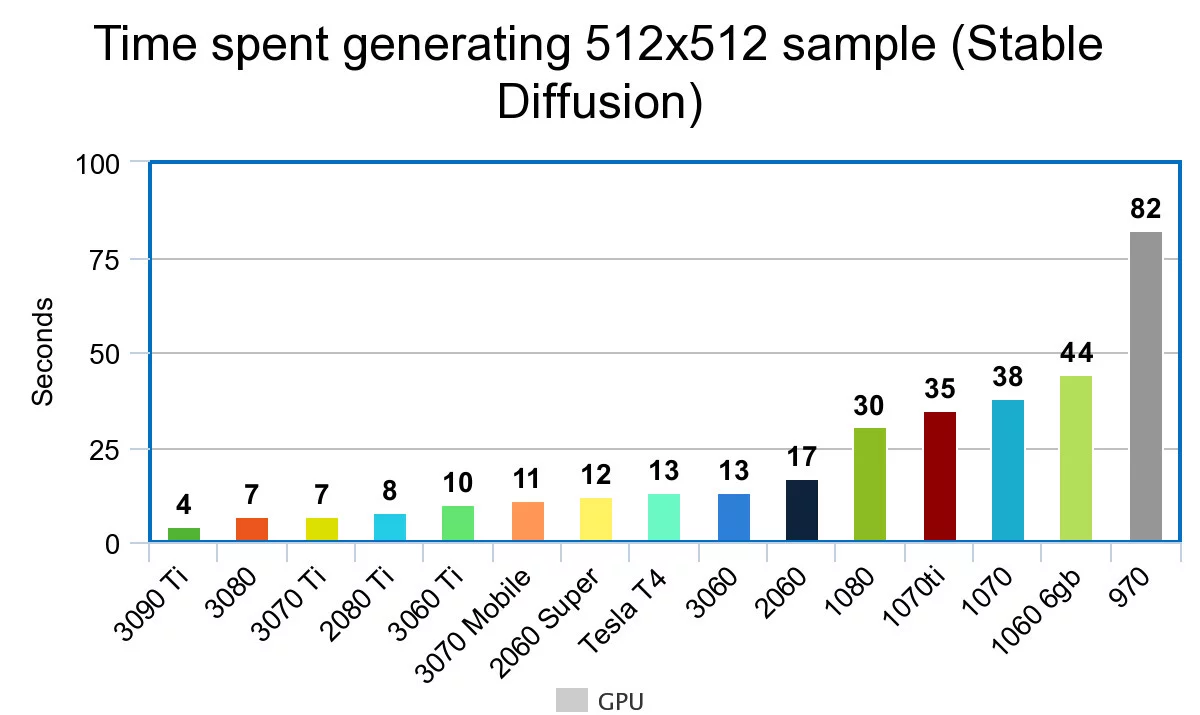
Один из вариантов, над которым мы сейчас думаем, — предоставлять людям, у которых есть свои мощности, специальное ПО. Ты скачиваешь программу, и сервис работает исключительно на твоей видеокарте. Ничего не надо настраивать, качать библиотеки, обучать — всё работает «в один клик».
VGTimes: По сути, аренда мощностей у самого себя?
Семен Шейн: Скорее «личный кабинет» в сервисе. Это банально быстрее. Представим, что ты — коммерческая организация, у которой есть необходимость круглосуточно использовать сервис. Сервис непостоянен — сегодня очередь минута, завтра — сто минут. Тебе, как предпринимателю, этот вариант не подходит.
Ты приходишь в магазин, покупаешь, к примеру, 30 видеокарт, устанавливаешь и с помощью нашего ПО получаешь выделенный канал для работы только над твоими задачами на твоих мощностях. Ну, это один из вариантов развития.
Вариаций, куда двигаться — масса. Сейчас, условно говоря, сервис «достраивается» — мы латаем дыры, что-то меняем, вводим новые функции. Изначально весь проект был сделан по принципу «а давайте попробуем». Попробовали. Не ожидали такого всплеска интереса.

Сейчас проект развивается на собственные средства и некоторые поступления со стороны, мы работаем «в минус». Конечно, это не наша основная работа. Можно назвать NeuroFox.pro хобби, которое вышло из-под контроля. Уже поступали предложения о выкупе сервиса от людей, которые видят в этом потенциальную прибыль.
К примеру, у нас есть одна знакомая, которая занимается визуализацией проектов загородных домов. Раньше она использовала специализированную программу, а теперь она делает визуализацию, прогоняет через нейросеть и продает результат клиентам за очень серьезные деньги зарубеж.
Причем сама нейросеть добавляет элементы, которые безумно нравятся клиентам. От заказов нет отбоя. Основные клиенты — из Китая, они сейчас очень платежеспособная аудитория. И это лишь один из вариантов. Человек подключился, платит условные 750 рублей, а продает проекты в сотни раз дороже.
VGTimes: У вас есть множество модулей, вроде Anything 3.0, NovelAI, MidiJorney. Все они — тренированные модели нейросетей, у которых свои веса и параметры, а сама Stable Diffusion всегда одна?
Семен Шейн: Да, грубо говоря, ядро — едино. А то, что мы сверху «допиливаем» — это наши наработки, задумки. У нас уже есть собственные уникальные модули, которых нигде не найти. Кроме того, у нас в плане написать дополнительное собственное ядро, к которому уже люди будут сами добавлять модули, которыми можно будет пользоваться.





VGTimes: Как считаете, нейросети заменят художников? И сколько на это уйдет времени?
Семен Шейн: Я считаю, что заменить художников они не смогут. Они станут невероятно полезным инструментом, но заменить — нет. Может быть, в каком-то отдаленном будущем, когда мы сможем научить нейросети 3D-модели, вопрос может встать остро. Но на сегодняшний день это инструмент для помощи.
VGTimes: Тогда немного перефразирую. Творцов, конечно, нейросети не заменят — всё же нейросети работают именно благодаря труду художников. Но что насчет иллюстраторов? К примеру, у меня есть черновик книги и мне нужна обложка и иллюстрации к ней. Реально ли это?
Семен Шейн: Теоретически — да. Такая нейросеть может заменить реальных иллюстраторов. Даже сейчас, если у тебя есть такой черновик, ты с нашим сервисом сможешь сделать себе иллюстрации.


Но, опять же, берём человека-фантаста, автора различных книг. Если он хорошо умеет писать и это — его самая сильная сторона, сможет ли он работать с нейросетью? Задать правильные веса, сумеет ли передать словами свою задумку? Нет, если ранее он с этим не работал.
Скорее он пойдет к тому, кто умеет делать иллюстрации, и этот специалист сделает их, даже, может быть, на нашем сервисе. Но когда будут разработаны удобные и понятные интерфейсы — тогда да, возможно, он сумеет сделать иллюстрации для своих книг самостоятельно.
Сейчас мы говорим про ИИ в зародыше. Потенциальных идей, как его развить — у нас масса. К примеру, у нас есть наметки кода для проекта, который бы генерировал ряд картинок на основе текстового описания, создавая полноценную историю. Но всё это, конечно, будет не сегодня и не завтра.
И опять же, всё упирается в мощности. Если все книжные издательства и энтузиасты начнут арендовать мощности для генерации обложек, иллюстраций, комиксов и артов — все системы будут перегружены. Ни одна из них не справится — мощностей не хватит.
VGTimes: Как думаете, что нас ждёт дальше? В плане других нейросетей, их применения, опасностей для различных профессий. Тот же zero-code или абстрактная постановка задач машинам, чтобы те писали на их основе алгоритмы. Когда-нибудь ведь это вырвется за пределы обычной генерации картинок и дипфейков.
Mr4erk: Как для программиста, для меня это прикладной инструмент для ускорения и упрощения рутинных или повседневных задач.
Что до рядового пользователя — сейчас нейросети повсюду: карты, видеонаблюдение, логистика, маркетинг. Насчёт zero-code — на текущий момент из того, что я видел, это лишь примитивные инструменты для решения примитивных задач. Взять ту же «Тильду» — инструмент для создания сайта с картинками и формочками.
Это отличный инструмент для малого бизнеса, где можно с нуля и практически без знаний сделать сайт, который уже сейчас может приносить заказы. Но стоит начать развиваться, когда схемы работы усложняются, то без программирования не обойтись.

Если брать SD и подобные технологии, то уже сейчас они доступны почти каждому рядовому пользователю. Однако прорыв будет за счет оптимизации алгоритмов работы, так как у всего железа есть предел. И заметен он будет у корпораций, остаётся только надеяться, что открытый код дойдет и до пользователей.
VGTimes: Семен, концепция сервиса, которую вы с Mr4erk описали, выглядит амбициозно. Будущее уже наступило?
Семен Шейн: Да, при этом мы затрагиваем только часть потенциала. Вспомнить ту же концепцию «No Code», над которой сейчас трудятся энтузиасты. Они хотят создать нейросеть, которая будет интерпретировать абстрактные задачи, буквально ТЗ, которые обычно ставят перед программистами, в готовый код.
Вроде «Напиши мне CRM-систему (программа для организации работы с клиентами, используемая в бизнесе — прим. редакции) вот с такими параметрами и возможностями». Потому что сейчас в интернете достаточно информации для того, чтобы нейросеть при грамотной настройке обучалась подобному.
Нейросети могут всё, изображения — наиболее наглядный способ продемонстрировать их потенциал, потому всё и завирусилось. Но ИИ продвигается не только в этом: автомобили Tesla, системы автоматизации, специализированные нейросети. У меня есть, условно, тетрадь, исписанная различными идеями, которые можно реализовать с помощью «нейронок». Единственная проблема — время. Его, конечно, не хватает.
Ну и, если возвращаться к NeuroFox, некоторые юридические проблемы, которые вытекают из возможностей Stable Diffusion. Есть, скажем так, определенная группа людей, которая может случайно или специально генерировать неприемлемый контент.
Конечно, в договоре оферты у нас прописана ответственность за генерацию подобных вещей, его подтверждают все пользователи сервиса. Да и плашка с предупреждением у нас на сайте висит. Но все же были случаи, когда подобный контент выкладывали в свободный доступ, при этом тегая наш сервис. За подобное творчество по законам стран СНГ есть уголовная ответственность.
И пусть технически мы лишь предоставляем инструмент, использовать который можно по-разному, несовершенство некоторых правовых аспектов ставит нас в трудное положение. С ростом сервиса будет расти и ответственность за то, что и как публикуют люди. Так что помимо положительных моментов у технологии нейросетей есть и опасные, и неудобные моменты.



Но мы работаем над решением этих проблем и развиваем сервис. К примеру, также у нас есть генератор историй на основе «Балабола» от Яндекса и чат-бот, который обучается по мере переписки. Так что Stable Diffusion — лишь одно из направлений нашей работы.
Конечно, наше развитие было бы невозможным без меценатов, которые делятся мощностями, и пользователей, которые дают обратную связь и сообщают об ошибках.
* * *
Наш материал дает самое базовое понимание того, как работает Stable Diffusion и нейросети. Для SD уже сейчас есть множество дополнений, скриптов и моделей, которые расширяют и без того внушительные возможности программы. Если вы хотите, чтобы мы разобрали какой-то конкретный аспект, плагин или функцию, пишите об этом в комментариях.
Что в целом думаете о нейросетях? Хотели бы научиться работать с ними?
Что думаете о будущем нейросетей?
-
![]() Художники против ИИ: на ArtStation началась настоящая война против нейросетей
Художники против ИИ: на ArtStation началась настоящая война против нейросетей -
![]() Интервью с руководителем разработки Gedonia 2 Олегом Казаковым: про использование нейросетей, похожесть на Breath of the Wild и кооперативный режим
Интервью с руководителем разработки Gedonia 2 Олегом Казаковым: про использование нейросетей, похожесть на Breath of the Wild и кооперативный режим -
![]() Нейросеть поиздевалась над персонажами «Звёздных войн» — они сильно набрали вес
Нейросеть поиздевалась над персонажами «Звёздных войн» — они сильно набрали вес -
![]() Disney показала впечатляющую нейросеть для изменения возраста. Она в реальном времени может состарить или омолодить человека
Disney показала впечатляющую нейросеть для изменения возраста. Она в реальном времени может состарить или омолодить человека -
![]() Создана новая нейросеть, которая генерирует музыку по текстовому описанию
Создана новая нейросеть, которая генерирует музыку по текстовому описанию -
![]() Нейросети на любой случай жизни: для создания видео, редактуры фото, написания текста и записи звука
Нейросети на любой случай жизни: для создания видео, редактуры фото, написания текста и записи звука -
![]() ТОП-40 лучших игр про выживание на PC
ТОП-40 лучших игр про выживание на PC -
![]() ТОП-70 игр в открытом мире. Вам точно будет, чем заняться
ТОП-70 игр в открытом мире. Вам точно будет, чем заняться -
![]() ТОП-20: лучшие кооперативные хорроры (2021-2025)
ТОП-20: лучшие кооперативные хорроры (2021-2025) -
![]() ТОП-30: лучшие кооперативные игры для PS4 и PS5 — во что поиграть с друзьями на одной консоли
ТОП-30: лучшие кооперативные игры для PS4 и PS5 — во что поиграть с друзьями на одной консоли -
![]() Лучшие мобильные игры для двоих на iOS и Android (на 2025 год)
Лучшие мобильные игры для двоих на iOS и Android (на 2025 год)