
Создана новая нейросеть, которая генерирует музыку по текстовому описанию
 Drako
Drako
В сети появилась новая генеративная нейросеть под названием Riffusion. С её помощью можно создавать музыку из текста. Новинка основана на Stable Diffusion версии 1.5.
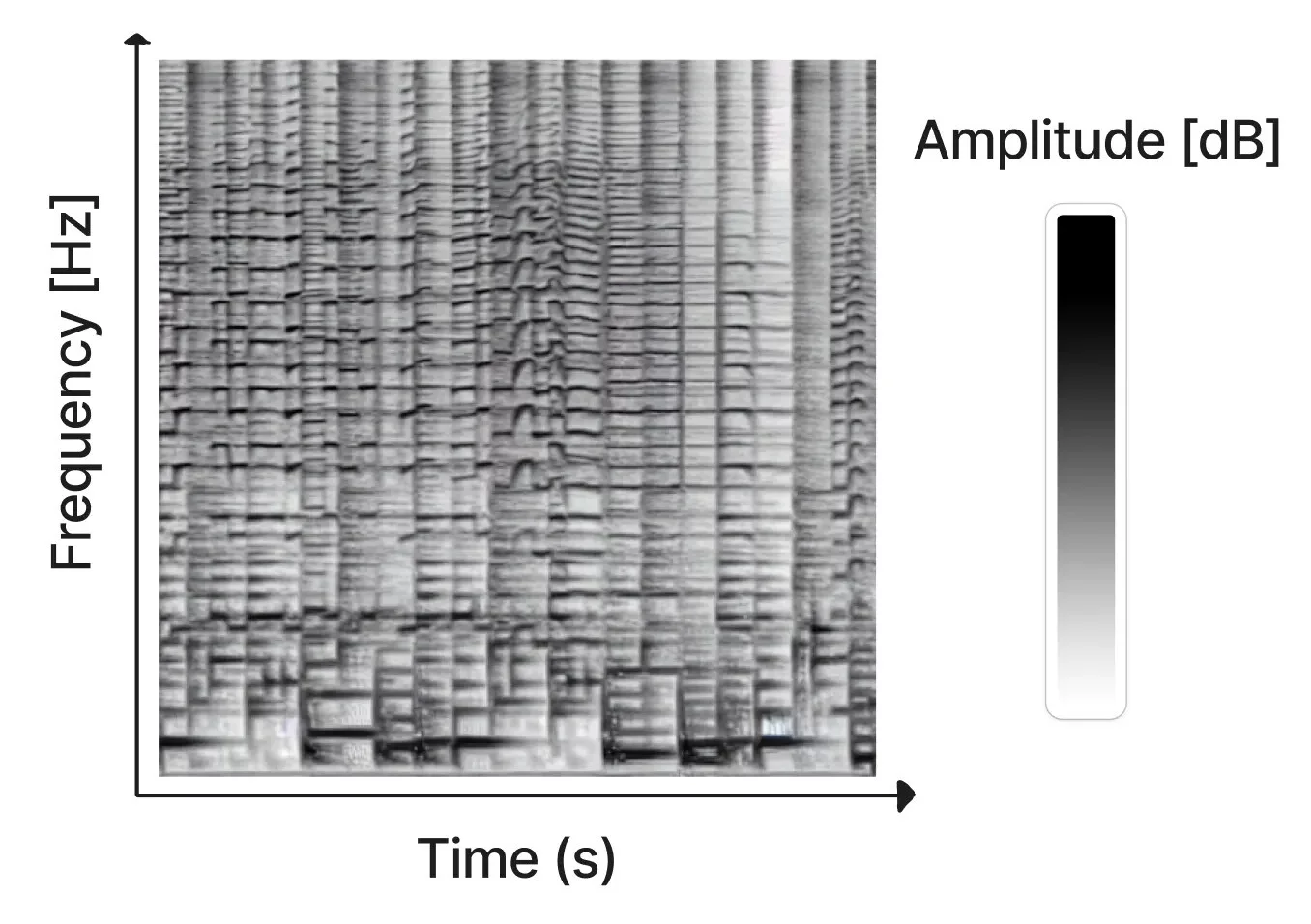
Идея состоит в том, что Stable Diffusion генерирует так называемые сонограммы или спектрограммы — визуальное представление музыки. Это обычная плоская картинка, где по на оси X показан порядок воспроизведения частот слева направо, а по оси Y — частота звука. Цвет пикселя же задаёт амплитуду звука в каждый момент времени.
Принцип работы прост: Stable Diffusion генерирует картинку и переводит её в спектрограмму, затем данные переводятся в звук с помощью библиотеки для обработки звука Torchaudio. В результате получается музыкальный трек. При этом в текстовом запросе можно указать жанр — рок, джаз и так далее. Даже можно сгенерировать звук набора на клавиатуре.
Попробовать самому новинку можно здесь.
-
![]() Нейросеть показала, как мог бы выглядеть «Джон Уик» в виде олдскульного аниме
Нейросеть показала, как мог бы выглядеть «Джон Уик» в виде олдскульного аниме -
![]() Нейросеть показала пожилого Донателло из «Черепашек-ниндзя». Герой уехал из Нью-Йорка и начал пить пиво
Нейросеть показала пожилого Донателло из «Черепашек-ниндзя». Герой уехал из Нью-Йорка и начал пить пиво -
![]() Нейросеть перенесла Бэтмена, Джокера и Харли Квин в пустоши «Безумного Макса»
Нейросеть перенесла Бэтмена, Джокера и Харли Квин в пустоши «Безумного Макса» -
![]() Нейросеть превратила Велму, Дафну и других героев «Скуби-Ду» в горячих моделей
Нейросеть превратила Велму, Дафну и других героев «Скуби-Ду» в горячих моделей -
![]() Нейросеть показала Генри Кавилла во вселенной Warhammer 40,000
Нейросеть показала Генри Кавилла во вселенной Warhammer 40,000




